
langchain接触
一些例子
简易:
from langchain_openai import ChatOpenAI
from langchain.schema import HumanMessage
import os
os.environ['OPENAI_API_KEY'] = 'API密钥'
os.environ['OPENAI_BASE_URL'] = '代理URL'
chat = ChatOpenAI(temperature=0.9, model_name="gpt-3.5-turbo-0125")
text = ('who are you?')
messsage = [HumanMessage(content=text)] #注意中括号
response = chat.invoke(messsage) #提示使用invoke
print(response)
模板:
from langchain.prompts import ChatPromptTemplate,SystemMessagePromptTemplate,HumanMessagePromptTemplate
from langchain_openai import ChatOpenAI
import os
os.environ['OPENAI_API_KEY'] = 'sk-gm0NJjYKwvRNRxstpWyEV1zDQvX9tfwNhlt8pjB7hlWvIDNt'
os.environ['OPENAI_BASE_URL'] = 'https://api.chatanywhere.tech/v1'
chat = ChatOpenAI(temperature=0.9, model_name="gpt-3.5-turbo-0125")
#系统消息模板
template = (
'you are a helpful assistant that translate {input} to {output}'
)
system_message_template = SystemMessagePromptTemplate.from_template(template)
#人类
human_template = '{text}'
human_message_template = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages([
system_message_template,
human_message_template
])
chain = chat_prompt | chat
response = chain.invoke({'input': 'chinese', 'output': 'english', 'text': '你是谁?'})
print(response)模型IO
无需了解各个平台的api调用协议
LLM模型包装器获得结果是字符串
聊天模型包装器获得AIMessage消息类型(更推荐?)
llm:
输入通常是单一提示词,主要用于文本任务
聊天包装器:
一系列聊天信息,返回AIMessage
聊天模型包装器
3个数据模式(schema)
AIMessage,HumanMessage,SystemMessage
输入类型必须是消息列表
from langchain.prompts import ChatPromptTemplate,SystemMessagePromptTemplate,HumanMessagePromptTemplate
from langchain_openai import ChatOpenAI
from langchain.schema import SystemMessage, HumanMessage, AIMessage
import os
os.environ['OPENAI_API_KEY'] = 'sk-gm0NJjYKwvRNRxstpWyEV1zDQvX9tfwNhlt8pjB7hlWvIDNt'
os.environ['OPENAI_BASE_URL'] = 'https://api.chatanywhere.tech/v1'
chat = ChatOpenAI(temperature=0.9, model_name="gpt-3.5-turbo-0125")
messages = [
SystemMessage(content='你是一个取名大师,你擅长为小孩取名字'),
HumanMessage(content='帮我的孩子取名,我姓汪,给我5个名字')
]
response = chat.invoke(messages)
print(response.content,end='\n') #.content解析返回的AIMessage
#如果不用content就会返回使用的token情况之类的信息模板
可能包含:明确的指令,少量示例,用户输入
内置:
from langchain.chains.api.prompt import API_RESPONSE_PROMPT
prompt = API_RESPONSE_PROMPT.format(api_docs = '',api_url='', question='',api_response='')
外部:自由添加的数据PromptTemplate包装类
构造提示词的过程就是实例化这个类的过程,这个实例化后的对象在各个组件中被调用
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate
import os
os.environ['OPENAI_API_KEY'] = 'sk-gm0NJjYKwvRNRxstpWyEV1zDQvX9tfwNhlt8pjB7hlWvIDNt'
os.environ['OPENAI_BASE_URL'] = 'https://api.chatanywhere.tech/v1'
chat = ChatOpenAI(temperature=0.9, model_name="gpt-3.5-turbo-0125")
template = '''你是一个文本优化大师,擅长将一段文本变得轻松幽默,以下是你需要优化的文本:{text}'''
#实例化
prompt = PromptTemplate.from_template(template)
final_prompt = prompt.format(text='你真是一个天才!')
response = chat.invoke(final_prompt)
print(response.content,end='\n')
#or
template = '''你是一个文本优化大师,擅长将一段文本变得轻松幽默,以下是你需要优化的文本:{text}'''
#实例化
prompt = PromptTemplate.from_template(template)
chain = prompt | chat
response = chain.invoke({'text':'今天天气真好,阳光明媚,适合出去游玩。'})
print(response.content,end='\n')
template = '''你是一个文本优化大师,擅长将一段文本变得轻松幽默,以下是你需要优化的文本:{text}'''
#实例化
prompt = PromptTemplate(template=template,input_variables=['text'])#指明变量是什么
final_prompt = prompt.format(text='今天天气真好,阳光明媚,适合出去游玩。')
response = chat.invoke(final_prompt)
print(response.content,end='\n')ChatPromptTemplate包装类
提示词是消息列表,输出Message对象
思路:先将SystemMessagePromptTemplate和HumanMessagePromptTemplate实例化,然后把他们俩传入ChatPromptTemplate
#系统消息模板
template = (
'you are a helpful assistant that translate {input} to {output}'
)
system_message_template = SystemMessagePromptTemplate.from_template(template)
#人类
human_template = '{text}'
human_message_template = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages([
system_message_template,
human_message_template
])
chain = chat_prompt | chat
response = chain.invoke({'input':'chinese','output':'english','text':'你好'}) #invoke要求输入一个dict
print(response.content,end='\n')
#or
template = (
'you are a helpful assistant that translate {input} to {output}'
)
system_message_template = SystemMessagePromptTemplate.from_template(template)
#人类
human_template = '{text}'
human_message_template = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages([
system_message_template,
human_message_template
])
final_prompt = chat_prompt.format_prompt(input='chinese',output='english',text='你好')#format也可行???format类型的指令传入关键字参数
response = chat.invoke(final_prompt)
print(response.content,end='\n')FewShotPromptTemplate包装类
动态添加,选择示例
example_selector 根据策略从示例中选取一部分,示例被嵌入提示词,没有这一项就需要提供一个示例列表
example_prompt是一个PromptTemplate对象,是和examples打配合的
prefix,suffix等价于template参数,suffix必填
examples = [{'input':'高','output':'矮'},
{'input':'大','output':'小'},
{'input':'快乐','output':'悲伤'},
{'input':'白','output':'黑'},]
example_prompt = PromptTemplate(template='''{input} 对应的相反词是 {output}''',
input_variables=['input','output'])
example_prompt.format(**examples[0])#解开键值对,作为关键字参数传入
few_shot_prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
example_separator='\n\n',
prefix='你是一个反义词接龙大师,我提供一个词语,你提供它的反义词.\n',
suffix='你先来,词语:{input}\n反义词: ',
input_variables=['input']
)
final_prompt = few_shot_prompt.format(input='高')
response = chat.invoke(final_prompt)
print(response.content,end='\n')示例选择器
示例过大,需要选择
根据输入长度?相似度?多样性?
LengthBasedExampleSelector
examples = [{'input':'高','output':'矮'},
{'input':'大','output':'小'},
{'input':'快乐','output':'悲伤'},
{'input':'白','output':'黑'},]
example_prompt = PromptTemplate(template='''{input} 对应的相反词是 {output}''',
input_variables=['input','output'])
example_prompt.format(**examples[0])#解开键值对,作为关键字参数传入
example_selector = LengthBasedExampleSelector(
examples=examples,
example_prompt=example_prompt,
max_length=25,
)
example_selector_prompt = FewShotPromptTemplate(
example_selector=example_selector,#这里就不是examples了
example_prompt=example_prompt,
example_separator='\n\n',
prefix = '你是一个反义词接龙大师,我提供一个词语,你提供它的反义词.\n',
suffix='你先来,词语:{input}\n反义词: ',
input_variables=['input']
)
final_prompt = example_selector_prompt.format(input='高')
response = chat.invoke(final_prompt)
print(response.content,end='\n')LengthBasedExampleSeletor : max_length
MaxMarginalRelevanceExampleSelector:嵌入类OpenAIEmbeddings()语义相似性测量,VectorStore类(FAISS) 存储嵌入类,执行相似性搜索 k生成示例数量
NGramOverlapExampleSelector:threshold示例选择器停止阈值
SenmanticSimilarityExampleSelector:OpenAIEmbeddings(),VectorStore(Chroma或其他) k生成示例数
每个示例选择器可以用函数方式实例化,也可以使用from_examples
example_selector = SenmanticSimilarityExampleSelector.from_example(
examples,
OpenAIEmbeddings(),
Chroma,
k=1
)多功能模板
Partial
已经创建了提示词模板对象,但没有明确输入变量
prompt = PromptTemplate(template='{foo}{bar}', input_variables=['foo','bar'])
partial_prompt = prompt.partial(foo='foo');#提前传递foo
print(partial_prompt.format(bar='b'))PipelinePrompt
组合模板,看书
序列化模板
JSON,YAML
prompt = load_prompt('few_shot_prompt.json')#加载外部模板文件输出解析器
原理:改变提示词模板,指导模型按照特定格式输出内容

使用:主要依靠partial方法或者实例化PromptTemplate对象时传入partial_variables参数
format_instructions = output_parser.get_format_instructions()#获取预设输出指令
prompt = PromptTemplate(
template='list 5 {obj}.\n{format_instructions}',
input_variables=['obj'],
partial_variables={'format_instructions':format_instructions}#dict,这样就在模板中添加了format_instructions,即输出指令字符串
)from langchain_openai import ChatOpenAI,OpenAI
from langchain.prompts import (FewShotPromptTemplate,
PromptTemplate,
ChatPromptTemplate,
HumanMessagePromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
LengthBasedExampleSelector)
import os
from langchain.output_parsers import CommaSeparatedListOutputParser
output_parser = CommaSeparatedListOutputParser()
os.environ['OPENAI_API_KEY'] = 'sk-gm0NJjYKwvRNRxstpWyEV1zDQvX9tfwNhlt8pjB7hlWvIDNt'
os.environ['OPENAI_BASE_URL'] = 'https://api.chatanywhere.tech/v1'
llm = OpenAI()
format_instructions = output_parser.get_format_instructions()#获取格式说明
prompt = PromptTemplate(template = 'list 5 {obj}.\n{format_instructions}',
input_variables=['obj'],
partial_variables= {'format_instructions':format_instructions})
chat = prompt | llm
output = chat.invoke('fruits')
#output = chat.invoke({'obj':'fruits'})
print(output_parser.parse(output))#['apple', 'banana', 'orange', 'strawberry', 'pineapple']Pydantic JSON输出
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import JsonOutputParser,PydanticOutputParser
from langchain_core.pydantic_v1 import BaseModel,Field
import os
os.environ['OPENAI_API_KEY'] = 'sk-gm0NJjYKwvRNRxstpWyEV1zDQvX9tfwNhlt8pjB7hlWvIDNt'
os.environ['OPENAI_BASE_URL'] = 'https://api.chatanywhere.tech/v1'
model = ChatOpenAI()
class Joke(BaseModel):#定义笑话的结构
setup : str = Field(description='question to setup a joke')
punchline : str = Field(description='answer to reslove the joke')
joke_query = 'Tell me a joke about cats.'
parser = JsonOutputParser(pydantic_object=Joke)
format_instructions = parser.get_format_instructions()
prompt = PromptTemplate(
template='anser the user query.\n{format_instructions}\n{query}\n',
input_variables=['query'],
partial_variables={'format_instructions': format_instructions},
)
chain = prompt | model | parser
output = chain.invoke({'query': joke_query})
print(output)pydantic
from typing import List
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import PromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field, validator #注意引入库
from langchain_openai import ChatOpenAI
# 定义您所需的数据结构。
class Joke(BaseModel):
setup: str = Field(description="用以引出笑话的问题")
punchline: str = Field(description="解答笑话的答案")
# 您可以使用Pydantic轻松添加自定义验证逻辑。
@validator("setup")
def question_ends_with_question_mark(cls, field):
if field[-1] != "?":
raise ValueError("问题形式不正确!")
return field
# 还有一个查询意图,用于提示语言模型填充数据结构。
joke_query = "告诉我一个笑话。"
# 设置解析器并将指令注入到提示模板中。
parser = PydanticOutputParser(pydantic_object=Joke)
prompt = PromptTemplate(
template="回答用户查询。\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
chain = prompt | model | parser
chain.invoke({"query": joke_query})结构化
from langchain_openai import OpenAI
from langchain_core.prompts import PromptTemplate
from langchain.output_parsers import ResponseSchema,StructuredOutputParser
import os
os.environ['OPENAI_API_KEY'] = 'sk-gm0NJjYKwvRNRxstpWyEV1zDQvX9tfwNhlt8pjB7hlWvIDNt'
os.environ['OPENAI_BASE_URL'] = 'https://api.chatanywhere.tech/v1'
#设置接受的响应模式
response_scheme = [
ResponseSchema(name = "answer", description = "The answer to the question"),
ResponseSchema(name = "source", description = "the website")
]
output_parser = StructuredOutputParser.from_response_schemas(response_scheme)
# 设置模板
format_instructions = output_parser.get_format_instructions()
prompt = PromptTemplate(
template='尽可能最好地回答用户问题.\n{question}\n{format_instructions}',
input_variables=['question'],
partial_variables={'format_instructions': format_instructions}
)
model = OpenAI()
chain = prompt | model | output_parser
response = chain.invoke({"question": "索马里首都是哪里?"})
print(response)数据连接
文档加载器(L)
from langchain_community.document_loaders import DirectoryLoader
loader = DirectoryLoader('path_to_directory', glob="**/*.txt")#glob控制加载哪些文件
docs = loader.load()
#显示进度条,需要安装tqdm库
loader = DirectoryLoader('../', glob="**/*.md", show_progress=True)
docs = loader.load()
#多线程
loader = DirectoryLoader('../', glob="**/*.md", use_multithreading=True)
docs = loader.load()
#修改加载模式
from langchain_community.document_loaders import TextLoader
loader = DirectoryLoader("../", glob="**/*.md", loader_cls=TextLoader)
docs = loader.load()其余建议官网仔细查看How-to guides | 🦜️🔗 LangChain
嵌入模型加载器(E)
from langchain_openai import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(api_key="...")
#多个文本嵌入为向量
embeddings = embeddings_model.embed_documents(
[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
)
len(embeddings), len(embeddings[0])
#单个查询嵌入为向量
embedded_query = embeddings_model.embed_query("What was the name mentioned in the conversation?")
embedded_query[:5]文档转换器(D)
向量存储库(V)
检索器(R)
链
invoke,batch,stream
from langchain_core.runnables import RunnableLambda
runnable = RunnableLambda(lambda x: str(x))
runnable.invoke(5)
# Async variant:
# await runnable.ainvoke(5)
'5'
'''返回一个结果'''
'''分批处理'''
from langchain_core.runnables import RunnableLambda
runnable = RunnableLambda(lambda x: str(x))
runnable.batch([7, 8, 9])
# Async variant:
# await runnable.abatch([7, 8, 9])
['7', '8', '9']
'''迭代器'''
from langchain_core.runnables import RunnableLambda
def func(x):
for y in x:
yield str(y)
runnable = RunnableLambda(func)
for chunk in runnable.stream(range(5)):
print(chunk)
# Async variant:
# async for chunk in await runnable.astream(range(5)):
# print(chunk)
''''''chain runnables
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")
chain = prompt | model | StrOutputParser()
analysis_prompt = ChatPromptTemplate.from_template("is this a funny joke? {joke}")
composed_chain = {"joke": chain} | analysis_prompt | model | StrOutputParser()
composed_chain.invoke({"topic": "bears"})
#函数
composed_chain_with_lambda = (
chain
| (lambda input: {"joke": input})
| analysis_prompt
| model
| StrOutputParser()
)
composed_chain_with_lambda.invoke({"topic": "beets"})
#pipe()
from langchain_core.runnables import RunnableParallel
composed_chain_with_pipe = (
RunnableParallel({"joke": chain})
.pipe(analysis_prompt)
.pipe(model)
.pipe(StrOutputParser())
)
composed_chain_with_pipe.invoke({"topic": "battlestar galactica"})multiplechains
from langchain_core.runnables import RunnablePassthrough
prompt1 = ChatPromptTemplate.from_template(
"生成一种 {attribute} 的颜色。只返回颜色的名称:"
)
prompt2 = ChatPromptTemplate.from_template(
"颜色 {color} 的水果是什么?只返回水果的名称:"
)
prompt3 = ChatPromptTemplate.from_template(
"国旗的颜色中有颜色 {color} 的国家是哪个?只返回国家的名称:"
)
prompt4 = ChatPromptTemplate.from_template(
"{fruit} 的颜色和 {country} 的国旗是什么?"
)
model_parser = model | StrOutputParser()
color_generator = (
{"attribute": RunnablePassthrough()} | prompt1 | {"color": model_parser}
)
color_to_fruit = prompt2 | model_parser
color_to_country = prompt3 | model_parser
question_generator = (
color_generator | {"fruit": color_to_fruit, "country": color_to_country} | prompt4
)分支,合并
planner = (
ChatPromptTemplate.from_template("关于 {input} 生成一个论点")
| ChatOpenAI()
| StrOutputParser()
| {"base_response": RunnablePassthrough()}
)
arguments_for = (
ChatPromptTemplate.from_template(
"列举 {base_response} 的优点或正面方面"
)
| ChatOpenAI()
| StrOutputParser()
)
arguments_against = (
ChatPromptTemplate.from_template(
"列举 {base_response} 的缺点或负面方面"
)
| ChatOpenAI()
| StrOutputParser()
)
final_responder = (
ChatPromptTemplate.from_messages(
[
("ai", "{original_response}"),
("human", "优点:\n{results_1}\n\n缺点:\n{results_2}"),
("system", "根据批评生成最终响应"),
]
)
| ChatOpenAI()
| StrOutputParser()
)
chain = (
planner
| {
"results_1": arguments_for,
"results_2": arguments_against,
"original_response": itemgetter("base_response"),
}
| final_responder
)promptllmparser
#添加停止序列
chain = prompt | model.bind(stop=["\n"])
#函数输出解析器
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser
chain = (
prompt
| model.bind(function_call={"name": "joke"}, functions=functions)
| JsonOutputFunctionsParser()
)
{'setup': '为什么熊不喜欢快餐?',
'punchline': '因为它们抓不住它!'}
from langchain.output_parsers.openai_functions import JsonKeyOutputFunctionsParser
chain = (
prompt
| model.bind(function_call={"name": "joke"}, functions=functions)
| JsonKeyOutputFunctionsParser(key_name="setup")
)
"为什么熊不穿鞋子?"一些例子
setup_and_retrieval = RunnableParallel(
{"context": retriever, "question": RunnablePassthrough()}
)
chain = setup_and_retrieval | prompt | model | output_parser首先创建一个包含两个条目的RunnableParallel对象。第一个条目
context将包含检索器获取的文档结果。第二个条目question将包含用户原始问题。为了传递问题,我们使用RunnablePassthrough复制该条目。将上一步生成的字典传递给
prompt组件。然后,它将用户输入(即问题)和检索到的文档(即上下文)用于构建提示,并输出一个PromptValue。model组件使用生成的提示,并传递给OpenAI LLM模型进行评估。模型生成的输出是一个ChatMessage对象。最后,
output_parser组件接受一个ChatMessage,并将其转换为Python字符串,返回invoke方法的结果。
记忆
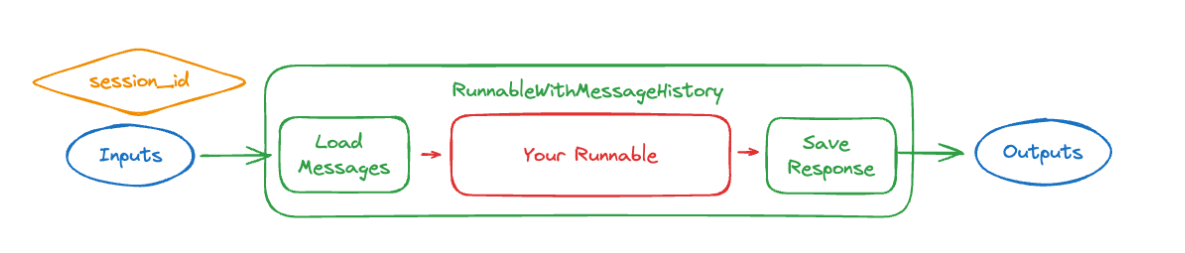
import os
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
from langchain_core.chat_history import BaseChatMessageHistory,InMemoryChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
os.environ['OPENAI_API_KEY'] = 'sk-gm0NJjYKwvRNRxstpWyEV1zDQvX9tfwNhlt8pjB7hlWvIDNt'
os.environ['OPENAI_BASE_URL'] = 'https://api.chatanywhere.tech/v1'
os.environ["LANGCHAIN_TRACING_V2"] = "False"
os.environ["LANGCHAIN_API_KEY"] = "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"
model = ChatOpenAI(model_name="gpt-3.5-turbo-0125", temperature=0.9)
store = {}
def get_session_history(session_id : str) -> BaseChatMessageHistory:#传入session_id,返回历史消息
if session_id not in store:
store[session_id] = InMemoryChatMessageHistory()
return store[session_id]
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful assistant. Answer all questions to the best of your ability in {language}.",
),
MessagesPlaceholder(variable_name="messages"),#传入messages
]
)
chain = prompt | model
with_message_history = RunnableWithMessageHistory(chain,get_session_history,input_messages_key='messages')
config = {'configurable':{'session_id':'abc2'}}
response = with_message_history.invoke({'language': 'English', 'messages': [HumanMessage(content="Hi,I'm Bob.How are you?")]},config=config)
print(response.content)
response = with_message_history.invoke(
{"messages": [HumanMessage(content="whats my name?")], "language": "chinese"},
config=config,
)
print(response.content)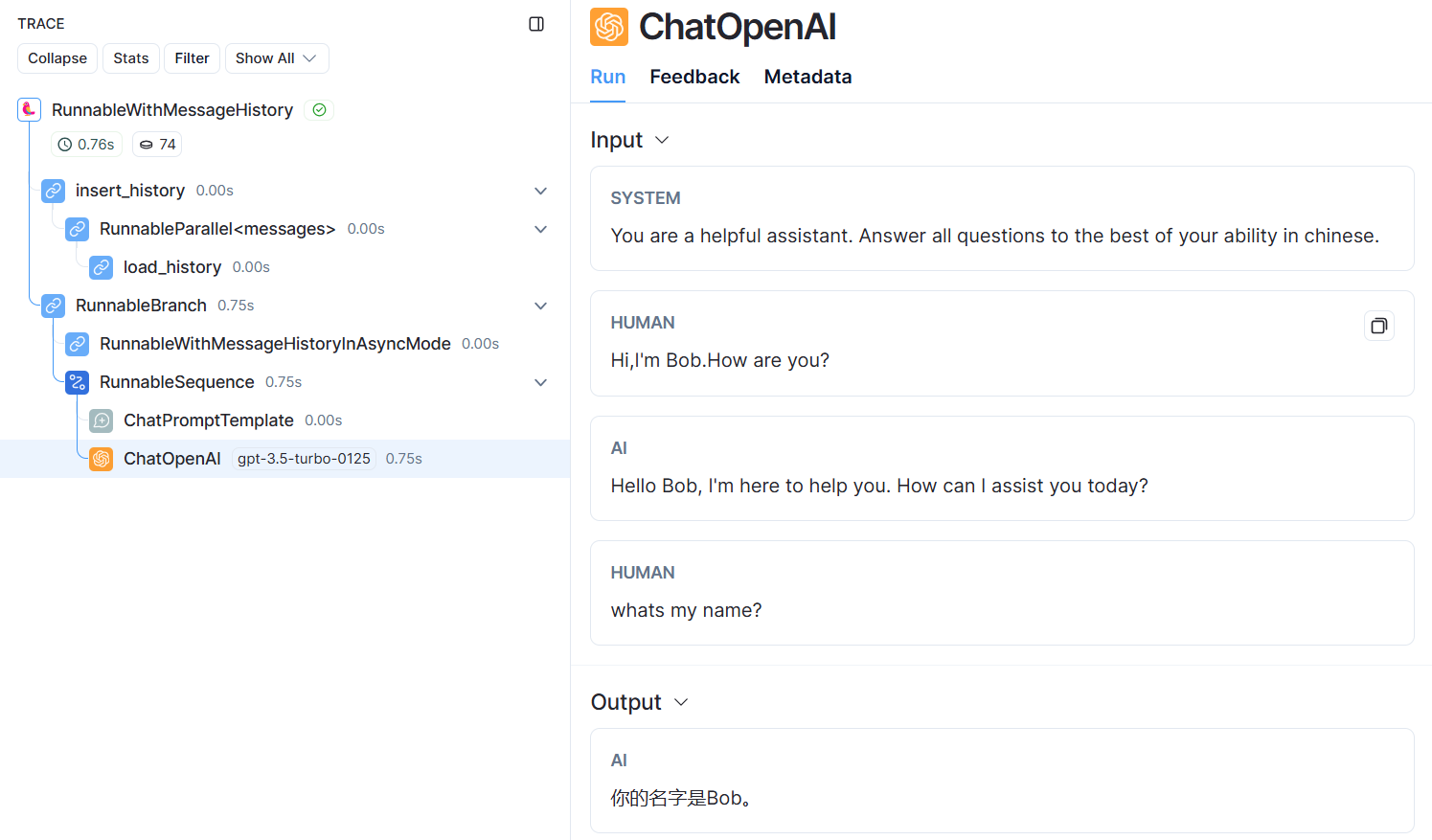
import os
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage,AIMessage
from langchain_core.chat_history import BaseChatMessageHistory,InMemoryChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_core.messages import SystemMessage,trim_messages
from operator import itemgetter
from langchain_core.runnables import RunnablePassthrough
os.environ['OPENAI_API_KEY'] = 'sk-gm0NJjYKwvRNRxstpWyEV1zDQvX9tfwNhlt8pjB7hlWvIDNt'
os.environ['OPENAI_BASE_URL'] = 'https://api.chatanywhere.tech/v1'
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "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"
model = ChatOpenAI(model_name="gpt-3.5-turbo-0125", temperature=0.9)
store = {}
messages = [
SystemMessage(content="you're a good assistant"),
HumanMessage(content="hi! I'm bob"),
AIMessage(content="hi!"),
HumanMessage(content="I like vanilla ice cream"),
AIMessage(content="nice"),
HumanMessage(content="whats 2 + 2"),
AIMessage(content="4"),
HumanMessage(content="thanks"),
AIMessage(content="no problem!"),
HumanMessage(content="having fun?"),
AIMessage(content="yes!"),
]
def get_session_history(session_id : str) -> BaseChatMessageHistory:#传入session_id,返回历史消息
if session_id not in store:
store[session_id] = InMemoryChatMessageHistory()
return store[session_id]
trimmer = trim_messages(
max_tokens = 65,
strategy = 'last',
token_counter = model,
include_system = True,
allow_partial = False,
start_on = 'human'
)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful assistant. Answer all questions to the best of your ability in {language}.",
),
MessagesPlaceholder(variable_name="messages"),#传入messages,暂时认为只有这么一种写法
]
)#需要传入language,messages(全)
chain = (
RunnablePassthrough.assign(messages = itemgetter('messages')| trimmer) | prompt | model
)
response = chain.invoke({'language': 'English', 'messages': messages + [HumanMessage(content="what math problem did i ask")]})#传入的messages是已有的messages加上一句HumanMessage
print(response.content)#'You asked "what\'s 2 + 2?"'
