
python爬虫学习
urllib模块
urllib.request请求,用于打开和读取urlurllib.error异常处理,urllib.parseurl解析urllib.roborparser解析robots.txt,判断哪些内容可以爬
打开一个案例
from urllib.request import urlopen
with urlopen('http://www.example.net') as html:
page = html.read()
print(page)urlopen函数
urllib.request.urlopen(url, data=None, timeout=socket._GLOBAL_DEFAULT_TIMEOUT,
*, cafile=None, capath=None, cadefault=False, context=None)
url:请求地址
data:发送到服务器的其他数据对象,类型是bytes,默认None,一旦使用,请求方式就变成POST了
timeout:超时时间
cafile和capath:ca证书及其路径
context:ssl.SSLContext类型,指定SSL设置
cadefault:已弃用
得到的是一个HTTPResponse对象,有以下方法:
read():读取整个网页数据getcode():获取网页状态码
getheaders():获取响应头内容;getheader(name):获取指定响应头;msg:信息属性;version:版本属性;status:状态属性。
注意!urlopen必须由urllib.request导入
from urllib.request import urlopen
from urllib.parse import urlencode
data=bytes(urlencode({'name':'germey'}).encode('utf-8'))
req=urlopen('https://www.httpbin.org/post',data=data)
print(req.read().decode('utf-8'))import socket
from urllib.request import urlopen
import urllib.error
try:
res=urlopen("https://www.httpbin.org/get",timeout=5)
print(res.read().decode('utf-8'))
except urllib.error.URLError as e:
if isinstance(e.reason, socket.timeout):
print("Connection timed out" )urllib.Request()抽象类 比单一urlopen更加强大
def __init__(self, url, data=None, headers={},
origin_req_host=None, unverifiable=False,
method=None)作用:?添加请求头?
仍然用urlopen发送请求,参数不是url,而是一个Request类型的对象
url:请求地址,必选参数;data:请求参数,必须为bytes类型数据,可以使用urlencode()进行编码;headers:字典类型,请求头设置;一般修改UA(User Agent)来伪装浏览器origin_req_host:请求的主机地址,IP 或域名;method:请求方法。
from urllib import request, parse
url = 'http://httpbin.org/post'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
}#模拟请求,避免被识别为爬虫
dict = {
'name': 'xiangpica'
}#要向网页发送的信息
# 转换数据类型,Request要求data必须是bytes类型
data = bytes(parse.urlencode(dict), encoding='utf8')
# 实例化Rquest对象
req = request.Request(url=url, data=data, headers=headers, method='POST')
# 添加请求头
req.add_header('HOST', 'httpbin.org')#可以在前面设定headers时就写好,也可以后面像这样加
# 发送数据
response = request.urlopen(req)
print(response.read().decode('utf-8'))from urllib import request, parse
url='https://www.httpbin.org/post'
headers={
'User-Agent':'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)',
'Host':'www.httpbin.org'
}
dict={
'name':'germey'
}
data=bytes(parse.urlencode(dict),encoding='utf-8')
req=request.Request(url=url,data=data,headers=headers,method='POST')
response=request.urlopen(req)
print(response.read().decode('utf-8'))字典->'name=xiangpica'->b'name=xiangpica'(bytes类型)
urlparse函数
主要用于解析URL
urllib.parse.urlparse(urlstring, scheme='', allow_fragments=True)scheme:协议类型,只有在URL中没有给出协议名才有用,若URL中有scheme,会返回解析出的scheme
返回一个ParseResult对象,是一个元组
urlunparse函数
参数必须有6个
from urllib import parse
data=['https','www.baidu.com','/index.html','user','a=6','comment']
print(parse.urlunparse(data))urlsplit函数,urlunsplit函数
与urlparse相似,但不单独解析params,将其合并进了path里,只返回5个结果
urljoin函数
给base_url,分析出scheme,netloc,path,并对新链接缺失部分进行补充,最后返回结果。

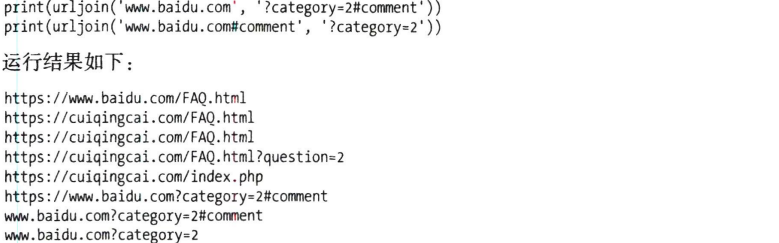
新链接如果没有scheme,netloc,path,就用base的补充,有就不替换。
urlencoder函数
事先用字典把参数写出来,然后将字典转换为URL的参数
parse_qs函数
反过来转换为字典
from urllib.parse import parse_qs
query_string = "name=John&age=30&city=New%20York"
parsed_query = parse_qs(query_string)
print(parsed_query) # {'name': ['John'], 'age': ['30'], 'city': ['New York']}quote,unquote函数
把内容转换为URL编码格式,URL中有中文时,可能导致乱码,用quote
from urllib.parse import quote
keyword='壁纸'
url = 'https://www.baidu.com/s?wd=' + quote(keyword)
print(url)#https://www.baidu.com/s?wd=%E5%A3%81%E7%BA%B8url格式
scheme://netloc/path;params?query#fragment
scheme:URL 协议;netloc:域名和端口;path:路径;params:最后一个路径元素参数,不常用;query:查询字符串;fragment:片段标志。
什么叫解析url?
from urllib.parse import urlparse
result = urlparse('http://www.example.com/index.html;info?id=10086#comment')
print(type(result), result)
print(result.scheme, result[0])
print(result.netloc, result[1])
print(result.path, result[2])
print(result.params, result[3])
print(result.query, result[4])
print(result.fragment, result[5])
'''
返回的是一个ParseResult对象,是一个具名元组(named tuple)
ParseResult(scheme='http', netloc='www.example.com', path='/index.html', params='info', query='id=10086', fragment='commment')
'''urlunparse()方法与上述方法逻辑相反;urljoin()方法用于拼接链接;urlencode():格式化请求参数;quote():将内容转换为 URL 编码格式,尤其是转换中文字符;unquote():对 URL 进行解码。
robotparser模块
分析网站Robots协议


RobotFileParser类
根据robots.txt判断是否有权限
urllib.robotparser.RobotFileParser(url='')

from urllib.robotparser import RobotFileParser
rp=RobotFileParser()
rp.set_url('https://www.baidu.com/robots.txt')
rp.read()
print(rp.can_fetch('BaiduSpider', 'https://www.baidu.com'))#True
print(rp.can_fetch('BaiduSpider', 'https://www.baidu.com/homepage/')) #True
print(rp.can_fetch('Googlebot', 'https://www.baidu.com/homepage/')) #FalseBaseHandler类
更高级操作,如Cookie处理,代理设置等


Request类和urlopen相当于已经封装好的常用请求方法,要实现高级功能,就需要进行深层配置
验证
from urllib.request import HTTPPasswordMgrWithDefaultRealm,HTTPBasicAuthHandler,build_opener
from urllib.error import URLError
username='admin'
password='admin'
url='https://ssr3.scrape.center/'
p=HTTPPasswordMgrWithDefaultRealm()
p.add_password(None,url,username,password)
auth_handler=HTTPBasicAuthHandler(p)#实例化对象,参数是HTTPPasswordMgrWithDefaultRealm对象
opener=build_opener(auth_handler)#opener类的open方法打开链接,完成验证
try:
result=opener.open(url)
html=result.read().decode('utf-8')
print(html)
except URLError as e:
print(e.reason)代理
from urllib.request import build_opener,ProxyHandler
from urllib.error import URLError
proxy_handler = ProxyHandler({'http':'http://127.0.0.1:8080','https':'http://127.0.0.1:8080'})
opener = build_opener(proxy_handler)
try:
response = opener.open('http://www.baidu.com')
print(response.read().decode('utf-8'))
except URLError as e:
print(e.reason)需要事先在本地搭建一个HTTP代理,让其运行在8080端口上
Cokkie
import http.cookiejar,urllib.request
cookie=http.cookiejar.CookieJar()#声明一个CookieJar对象
handler=urllib.request.HTTPCookieProcessor(cookie)#用HTTPCookieProcessor来创建Handler
opener=urllib.request.build_opener(handler)#构建opener
response=opener.open('http://www.baidu.com')#执行open函数
for item in cookie:
print(item.name+'='+item.value)import http.cookiejar,urllib.request
filename='cookie.txt'#设置保存cookie的文件,同级目录下
cookie=http.cookiejar.MozillaCookieJar(filename)#创建MozillaCookieJar对象
handler=urllib.request.HTTPCookieProcessor(cookie)#用HTTPCookieProcessor来创建Handler
opener=urllib.request.build_opener(handler)#构建opener
response=opener.open('http://www.baidu.com')#执行open函数
cookie.save(ignore_discard=True,ignore_expires=True)#保存cookie到cookie.txt中
for item in cookie:
print(item.name+'='+item.value)import http.cookiejar,urllib.request
cookie=http.cookiejar.MozillaCookieJar()#创建MozillaCookieJar对象
cookie.load('cookie.txt',ignore_discard=True,ignore_expires=True)#从文件中读取cookie内容到变量
handler=urllib.request.HTTPCookieProcessor(cookie)#用HTTPCookieProcessor来创建Handler
opener=urllib.request.build_opener(handler)#构建opener
response=opener.open('http://www.baidu.com')#执行open函数
print(response.read().decode('utf-8'))#打印响应内容处理异常
URLError:有reason属性,返回错误原因
HTTPError:是URLError的子类,由code(状态码),reason,headers(请求头)属性
可以先捕获HTTPError,再捕获URLError
from urllib import request,error
try:
resaponse=request.urlopen('https://cuiqingcai.com/404')
except error.HTTPError as e:
print(e.code,e.reason,e.headers,sep='\n')
except error.URLError as e:
print(e.reason)
else:
print('Request Successfully')requests模块
urllib有许多不方便的地方,处理验证和Cookie时需要些Handler和Opener,实现GET和POST也不方便
requests模块,更加强大
import requests
r=requests.get('https://www.baidu.com/')
print(type(r))
print(r.status_code)
print(type(r.text))
print(r.text[:100])
print(r.cookies)GET
import requests
r=requests.get("https://www.httpbin.org/get")
print(r.text)要发送额外信息呢
import requests
data={
"name":"germey",
"age":23
}
r=requests.get("https://www.httpbin.org/get",params=data)
print(r.text)想要得到json结果,需要调用json方法
import requests
r=requests.get("https://www.httpbin.org/get")
print(type(r.text))
print(r.json())
print(type(r.json()))爬图片
import requests
r=requests.get('https://scrape.center/favicon.ico')
with open('favicon.ico','wb') as f:#第一个:文件名 第二个:二进制写的方式
f.write(r.content)添加请求头
import requests
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
r=requests.get('https://ssr1.scrape.center/',headers=headers)
print(r.text)POST
import requests
data={'name':'John','age':30}
response=requests.post('http://httpbin.org/post',data=data)
print(response.text)高级用法
文件上传
import requests
files={'file': open('favicon.ico', 'rb')}
r=requests.post('https://httpbin.org/post', files=files)
print(r.text)文件上传会单独用一个files字段,网页响应中form字段是空的
Cookie设置
#获取cookie
import requests
r=requests.get('https://baidu.com')
print(r.cookies)#注意是cookies属性,有个s
for key,value in r.cookies.items():#用items方法转换为元组组成的列表
print(key+'='+value)
Session维持
import requests
requests.get('https://httpbin.org/cookies/set/number/123456789')
r=requests.get('https://httpbin.org/cookies')
print(r.text)#没有结果
import requests
s=requests.Session()
s.get('https://httpbin.org/cookies/set/number/123456789')
r=s.get('https://httpbin.org/cookies')
print(r.text)#有结果SSL证书验证
有些网站可能没设置好HTTPS证书,或者证书不被认可,会出现SSL证书出错的提示。
import requests
r=requests.get('https://ssr2.scrape.center/',verify=False)
print(r.status_code)#会报一个警告,处理方式比较多
#其中一种:
import requests
r=requests.get('https://ssr2.scrape.center/',cert=('/path/server.crt','/path/server.key'))#本地crt和key文件,key必须解密
print(r.status_code)超时
#超时分为连接和读取两个阶段
import requests
r=requests.get('https://httpbin.org/get',timeout=1)
#r=requests.get('https://httpbin.org/get',timeout=(5,30))分别设置时间
print(r.status_code)身份认证
import requests
r=requests.get('https://ssr3.scrape.center/',auth=('admin','admin'))
print(r.status_code)#成功200,失败401代理
import requests
proxies={
'http': 'http://10.10.1.10:3128',
'https': 'http://10.10.1.10:1080'
}#需要找代理
requests.get('http://example.org', proxies=proxies)正则表达式
re 库是 Python 中处理正则表达式的标准库
原生字符串
raw string
my_str=r'C:\number'#raw string,不会再换行
print(my_str)re.search
该函数用于,在字符串中搜索正则表达式匹配到的第一个位置的值,返回 match 对象。
'''
re.search(pattern,string,flags=0) 原型
flags:
re.I, re.IGNORECASE:忽略正则表达式的大小写;
re.M, re.MULTILINE:正则表达式中的 ^ 操作符能够将给定字符串的每行当做匹配的开始;
re.S, re.DOTALL:正则表达式中的 . 操作符能够匹配所有字符。
'''
import re
my_str='梦想橡皮擦 good good'
pattern = r'橡皮擦'
ret = re.search(pattern,my_str)#ret是一个match对象,有group方法
print(ret)
#<re.Match object; span=(2, 5), match='橡皮擦'>
print(ret.group(0))
'''
0:输出整个匹配到的字符串
1:输出第一个捕获组
'''re.match
该函数用于在目标字符串开始位置去匹配正则表达式,返回 match 对象,未匹配成功返回 None
import re
my_str = '梦想橡皮擦 good good'
pattern = r'梦' # 匹配到数据
#pattern = r'good' 匹配不到数据
ret = re.match(pattern, my_str)#match对象,有group方法
if ret:
print(ret.group(0))
re.match和re.search方法都是一次最多返回一个匹配对象,如果希望返回多个值,
可以通过在pattern里加括号构造匹配组返回多个字符串。
pattern = r'(梦想)(橡皮擦)'
re.findall
该函数用于搜索字符串,以列表格式返回全部匹配到的字符串
import re
my_str = '梦想橡皮擦 good good'
pattern = r'good'
ret = re.findall(pattern, my_str)#列表类型
print(ret)
#输出['good', 'good']re.split
该函数将一个字符串按照正则表达式匹配结果进行分割,返回一个列表。
re.split 函数进行分割的时候,如果正则表达式匹配到的字符恰好在字符串开头或者结尾,
返回分割后的字符串列表首尾都多了空格,需要手动去除
re.split(pattern, string, maxsplit=0, flags=0) 原型
import re
my_str = '1梦想橡皮擦1good1good1'
pattern = r'\d'#匹配数字
ret = re.split(pattern, my_str)#列表类型
print(ret)#['', '梦想橡皮擦', 'good', 'good', '']如果在 pattern 中捕获到括号,那括号中匹配到的结果也会在返回的列表中
import re
my_str = '1梦想橡皮擦1good1good1'
pattern = r'(\d)'
ret = re.split(pattern, my_str)
print(ret)#['', '1', '梦想橡皮擦', '1', 'good', '1', 'good', '1', '']re.finditer
import re
my_str = '1梦想橡皮擦1good1good1'
pattern = r'good'
# ret = re.split(pattern, my_str, maxsplit=1)
ret =re.finditer(pattern, my_str)#迭代器类型,每个元素都是match类型
print(ret)#<callable_iterator object at 0x000002AB69F2A500>re.sub
在一个字符串中替换被正则表达式匹配到的字符串,返回替换后的字符串
re.sub(pattern,repl,string,count=0,flags=0) 原型
import re
my_str = '1梦想橡皮擦1good1good1'
pattern = r'good'
ret = re.sub(pattern, "nice", my_str)
print(ret)beautiful soup
pip install bs4 -i https://mirrors.aliyun.com/pypi/simple/
pip install lxml -i https://mirrors.aliyun.com/pypi/simple/
import requests
from bs4 import BeautifulSoup
def ret_html():
"""获取HTML元素"""
res = requests.get('https://www.crummy.com/software/BeautifulSoup/', timeout=3)
return res.text
if __name__ == '__main__':
html_str = ret_html()
soup = BeautifulSoup(html_str, 'lxml')
print(soup)
'''
soup_beautiful = soup.prettify()
print(soup_beautiful)
prettify方法使结果更美观
'''BeautifulSoup对象
本身就代表整个 HTML 页面,而且实例化该对象的时候,还会自动补齐 HTML 代码。
html_str = ret_html()
soup = BeautifulSoup(html_str, 'lxml')
print(type(soup))tag对象
Tag 是标签的意思,Tag 对象就是网页标签,或者叫做网页元素对象,例如获取 bs4 官网的 h1 标签对象,代码如下所示:
if __name__ == '__main__':
html_str = ret_html()
soup = BeautifulSoup(html_str, 'lxml')
# print(soup.prettify()) # 格式化 HTML
print(soup.h1)#<h1>Beautiful Soup</h1>tag对象自然有对应的属性:
print(soup.h1)
print(type(soup.h1))
print(soup.h1.name) # 获取标签名称
print(soup.img) # 获取网页第一个 img 标签
print(soup.img['src']) # 获取网页元素DOM的属性值
print(soup.img.attrs) # 获取网页元素的所有属性值,以字典形式返回NavigableString对象
NavigableString 对象获取的是标签内部的文字内容
nav_obj = soup.h1.string #如果是单标签,会获取None
print(type(nav_obj))
print(soup.h1.text)
print(soup.p.get_text())
print(soup.p.get_text('&'))
'''
其中 text 是获取所有子标签内容的合并字符串,而 get_text() 也是相同的效果,不过使用 get_text() 可以增加一个分隔符,例如上述代码的 & 符号,还可以使用,strip=True 参数去除空格。
'''BeautifulSoup 对象和 Tag 对象支持标签查找
find() 方法和 find_all() 方法
obj.find(name,attrs,recursive,text,**kws)
obj.find_all(name,attrs,recursive,text,limit)
name:标签名称;attrs:标签属性;recursive:默认搜索所有后代元素;text:标签内容。limit参数,它表示最多返回的匹配数量,find()方法可以看作limit=1
#找a标签
html_str = ret_html()
soup = BeautifulSoup(html_str, 'lxml')
print(soup.find('a'))
#使用attrs参数找a标签
print(soup.find(attrs={'class': 'cta'}))
print(soup.find(class_='cta'))#等等......lxml
lxml.etree(待补充)
在爬虫代码采集过程中,通过 etree.HTML 直接将字符串实例化为 element 对象。
import requests
from lxml import etree
res = requests.get("http://www.jsons.cn/zt/")
html = res.text
root_element = etree.HTML(html)
print(root_element)
print(root_element.tag)XPath(待补充)
在爬虫代码编写中,直接使用 html.xpath("xpath表达式") 即可获取目标数据,例如获取网页 title。
print(root_element.xpath('//title'))
获取到 element 对象之后,可调用 text 属性,获取对应文本,在使用的时候,需要注意使用 XPath 获取到的 element 对象,都是列表。
title_element = root_element.xpath('//title')
print(title_element[0].text)
requests模块(待补充)
https://docs.python-requests.org/zh_CN/latest/
url:请求地址;params:要发送的查询字符串,可以为字典,列表,元组,字节;data:body 对象中要传递的参数,可以为字段,列表,元组,字节或者文件对象;json:JSON 序列化对象;headers:请求头,字典格式;cookies:传递 cookie,字段或CookieJar类型;files:最复杂的一个参数,一般出现在POST请求中,格式举例"name":文件对象或者{'name':文件对象},还可以在一个请求中发送多个文件,不过一般爬虫场景不会用到;auth:指定身份验证机制;timeout:服务器等待响应时间,在源码中检索到可以为元组类型,这个之前没有使用过,即(connect timeout, read timeout);allow_redirects:是否允许重定向;proxies:代理;verify:SSL 验证;stream:流式请求,主要对接流式 API;cert:证书。
使用 requests 库请求之后,会得到一个 Response 对象,掌握该对象的技巧就是了解其属性与方法
help(res)
print(dir(res))常用属性:
ok:只要状态码status_code小于 400,都会返回 True;is_redirect:重定向属性;content:响应内容,字节类型;text:响应内容,Unicode 类型;status_code:响应状态码;url:响应的最终 URL 位置;encoding:当访问r.text时的编码;
常用方法:
json():将响应结果序列化为 JSON;
会话对象
该对象能够在跨域请求的时候,保持住某些参数,尤其是 cookie,如果你想向同一主机发送多个请求,使用会话对象可以将底层的 TCP 连接进行重用,从而带来显著的性能提升。在发起requests对象以前,添加:
# 建立会话对象
s = requests.Session()
# 后续都使用会话对象进行进行,而不是直接使用 requests 对象
s.get('http://httpbin.org/cookies/set/sessioncookie/123456789')
r = s.get("http://httpbin.org/cookies")
print(r.text)