
langchain进阶
使用postgresql存储memory
from langchain_community.chat_message_histories import (
PostgresChatMessageHistory,
)
history = PostgresChatMessageHistory(
connection_string="postgresql://postgres:12345678@localhost/chat_history",
session_id="foo",
)
history.add_user_message("hi!")
history.add_ai_message("whats up?")注意这种方法在之后langchain更新后就弃用了
向量存储以及数据检索
document属性:page_content, metadata(包含任意元数据的字典)
这个测试项目使用的是Chroma,使用的是内存
from langchain_core.documents import Document
documents = [
Document(
page_content="Dogs are great companions, known for their loyalty and friendliness.",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="Cats are independent pets that often enjoy their own space.",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="Goldfish are popular pets for beginners, requiring relatively simple care.",
metadata={"source": "fish-pets-doc"},
),
Document(
page_content="Parrots are intelligent birds capable of mimicking human speech.",
metadata={"source": "bird-pets-doc"},
),
Document(
page_content="Rabbits are social animals that need plenty of space to hop around.",
metadata={"source": "mammal-pets-doc"},
),
]这里是自建了文档数据
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
vectorstore = Chroma.from_documents(
documents,
embedding = OpenAIEmbeddings()
)from_documents()
vectorstore.similarity_search('cat')
#or
vectorstore.similarity_search_with_score("cat")
#or
embedding = OpenAIEmbeddings().embed_query("cat")
vectorstore.similarity_search_by_vector(embedding)vector store是没法集成到链里的,需要使用retrievers
retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 1},
)
retriever.batch(["cat", "shark"])支持similarity,mmr(maximum marginal relevance),similarity_score_threshold 设置相似度阈值
Agent
本例子目的是让llm使用搜索功能
from langchain_core.messages import HumanMessage
import os
os.environ['TAVILY_API_KEY'] = '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'
from langchain_openai import ChatOpenAI
os.environ['OPENAI_API_KEY'] = 'sk-gm0NJjYKwvRNRxstpWyEV1zDQvX9tfwNhlt8pjB7hlWvIDNt'
os.environ['OPENAI_BASE_URL'] = 'https://api.chatanywhere.tech/v1'
model = ChatOpenAI()from langchain_community.tools.tavily_search import TavilySearchResults
search = TavilySearchResults(max_results= 2 )
search_results = search.invoke("what the weather is in Beijing")
print(search_results)
tools = [search]建tools,后面会用
model_with_tools = model.bind_tools(tools)注意对比!
response = model_with_tools.invoke([HumanMessage(content="Hi!")])
print(f"ContentString: {response.content}")
print(f"ToolCalls: {response.tool_calls}")
'''
ContentString: Hello! How can I assist you today?
ToolCalls: []
'''
response = model_with_tools.invoke([HumanMessage(content="What's the weather in SF?")])
print(f"ContentString: {response.content}")
print(f"ToolCalls: {response.tool_calls}")
'''
ContentString:
ToolCalls: [{'name': 'tavily_search_results_json', 'args': {'query': 'weather in San Francisco'}, 'id': 'call_aDc4g6dKUTizu24uEPPdPhIY', 'type': 'tool_call'}]
'''接下来建agent
from langgraph.prebuilt import create_react_agent
agent_executor = create_react_agent(model, tools)
#传入model,而不是model_with_tools,因为create_react_agent将在底层为我们调用.bind_tools。response = agent_executor.invoke({"messages": [HumanMessage(content="hi!")]})
response["messages"]
'''[HumanMessage(content='hi!', id='5b5f0f27-de01-4285-ade1-9c763176a2ff'),
AIMessage(content='Hello! How can I assist you today?', response_metadata={'token_usage': {'completion_tokens': 10,
'prompt_tokens': 83, 'total_tokens': 93}, 'model_name': 'gpt-3.5-turbo-0125', 'system_fingerprint': None, 'finish_reason': 'stop',
'logprobs': None}, id='run-ab19db63-8df9-4951-a938-4874eeeb74b0-0', usage_metadata={'input_tokens': 83, 'output_tokens': 10, 'total_tokens': 93})]
'''response = agent_executor.invoke(
{"messages": [HumanMessage(content="whats the weather in sf?")]}
)
response["messages"]返回消息流
for chunk in agent_executor.stream(
{"messages": [HumanMessage(content="whats the weather in sf?")]}
):
print(chunk)
print("----")
'''
{'agent': {'messages': [AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_50Kb8zHmFqPYavQwF5TgcOH8', 'function': {'arguments': '{\n "query": "current weather in San Francisco"\n}', 'name': 'tavily_search_results_json'}, 'type': 'function'}]}, response_metadata={'token_usage': {'completion_tokens': 23, 'prompt_tokens': 134, 'total_tokens': 157}, 'model_name': 'gpt-4', 'system_fingerprint': None, 'finish_reason': 'tool_calls', 'logprobs': None}, id='run-042d5feb-c2cc-4c3f-b8fd-dbc22fd0bc07-0', tool_calls=[{'name': 'tavily_search_results_json', 'args': {'query': 'current weather in San Francisco'}, 'id': 'call_50Kb8zHmFqPYavQwF5TgcOH8'}])]}}
----
{'action': {'messages': [ToolMessage(content='[{"url": "https://www.weatherapi.com/", "content": "{\'location\': {\'name\': \'San Francisco\', \'region\': \'California\', \'country\': \'United States of America\', \'lat\': 37.78, \'lon\': -122.42, \'tz_id\': \'America/Los_Angeles\', \'localtime_epoch\': 1714426906, \'localtime\': \'2024-04-29 14:41\'}, \'current\': {\'last_updated_epoch\': 1714426200, \'last_updated\': \'2024-04-29 14:30\', \'temp_c\': 17.8, \'temp_f\': 64.0, \'is_day\': 1, \'condition\': {\'text\': \'Sunny\', \'icon\': \'//cdn.weatherapi.com/weather/64x64/day/113.png\', \'code\': 1000}, \'wind_mph\': 23.0, \'wind_kph\': 37.1, \'wind_degree\': 290, \'wind_dir\': \'WNW\', \'pressure_mb\': 1019.0, \'pressure_in\': 30.09, \'precip_mm\': 0.0, \'precip_in\': 0.0, \'humidity\': 50, \'cloud\': 0, \'feelslike_c\': 17.8, \'feelslike_f\': 64.0, \'vis_km\': 16.0, \'vis_miles\': 9.0, \'uv\': 5.0, \'gust_mph\': 27.5, \'gust_kph\': 44.3}}"}, {"url": "https://world-weather.info/forecast/usa/san_francisco/april-2024/", "content": "Extended weather forecast in San Francisco. Hourly Week 10 days 14 days 30 days Year. Detailed \\u26a1 San Francisco Weather Forecast for April 2024 - day/night \\ud83c\\udf21\\ufe0f temperatures, precipitations - World-Weather.info."}]', name='tavily_search_results_json', id='d88320ac-3fe1-4f73-870a-3681f15f6982', tool_call_id='call_50Kb8zHmFqPYavQwF5TgcOH8')]}}
----
{'agent': {'messages': [AIMessage(content='The current weather in San Francisco, California is sunny with a temperature of 17.8°C (64.0°F). The wind is coming from the WNW at 23.0 mph. The humidity is at 50%. [source](https://www.weatherapi.com/)', response_metadata={'token_usage': {'completion_tokens': 58, 'prompt_tokens': 602, 'total_tokens': 660}, 'model_name': 'gpt-4', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None}, id='run-0cd2a507-ded5-4601-afe3-3807400e9989-0')]}}
----
'''可真多(O-O)
添加记忆模块
from langgraph.checkpoint.sqlite import SqliteSaver
memory = SqliteSaver.from_conn_string(":memory:")
agent_executor = create_react_agent(model, tools, checkpointer=memory)
config = {"configurable": {"thread_id": "abc123"}}
for chunk in agent_executor.stream(
{"messages": [HumanMessage(content="hi im bob!")]}, config
):
print(chunk)
print("----")
for chunk in agent_executor.stream(
{"messages": [HumanMessage(content="whats my name?")]}, config
):
print(chunk)
print("----")streaming
您可以在链中使用生成器函数(即使用yield关键字并表现得像迭代器的函数)。这些生成器的签名应为 Iterator[Input] -> Iterator[Output]。
一个自定义输出解析器的示例,用于处理以逗号分隔的列表:
from typing import Iterator, List
prompt = ChatPromptTemplate.from_template(
"Write a comma-separated list of 5 animals similar to: {animal}. Do not include numbers"
)
str_chain = prompt | model | StrOutputParser()
for chunk in str_chain.stream({"animal": "bear"}):
print(chunk, end="", flush=True)
# This is a custom parser that splits an iterator of llm tokens
# into a list of strings separated by commas
def split_into_list(input: Iterator[str]) -> Iterator[List[str]]:
# hold partial input until we get a comma
buffer = ""
for chunk in input:
# add current chunk to buffer
buffer += chunk
# while there are commas in the buffer
while "," in buffer:
# split buffer on comma
comma_index = buffer.index(",")
# yield everything before the comma
yield [buffer[:comma_index].strip()]
# save the rest for the next iteration
buffer = buffer[comma_index + 1 :]
# yield the last chunk
yield [buffer.strip()]
list_chain = str_chain | split_into_list
for chunk in list_chain.stream({"animal": "bear"}):
print(chunk, flush=True)
list_chain.invoke({"animal": "bear"})
#['lion', 'tiger', 'wolf', 'gorilla', 'raccoon']Runnable系列函数
RunnableParallel
RunnableParallel 原语本质上是一个字典,其值是可运行的对象(或可以被强制转换为可运行对象的事物,如函数)。它并行运行所有值,并且每个值都使用 RunnableParallel 的整体输入进行调用。最终返回值是一个字典,包含每个值在其相应键下的结果。
RunnableParallels 对于并行化操作非常有用,但也可以用于将一个 Runnable 的输出调整为下一个 Runnable 在序列中的输入格式。
# 提示词
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| output_parser
)
res = chain.invoke("how can langsmith help with testing?")
print(res)
# 将用户输入作为“question”键下的值传递过去。
# 问题 下面这样可以么?
res = chain.invoke({"question": "how can langsmith help with testing?"})
不行,相当于:"question":{"question": "how can langsmith help with testing?"}
# 可以是这样
{"context": retriever, "question": RunnablePassthrough()}
# 可以是这样
RunnableParallel({"context": retriever, "question": RunnablePassthrough()})
# 可以是这样
RunnableParallel(context=retriever, question=RunnablePassthrough())
#也可以用itemgetter
chain = (
# 原来是这样 {"context": retriever, "question": RunnablePassthrough()}
{
"context": itemgetter("question") | retriever, <----------
"question": itemgetter("question"), <---------
}
| prompt
| model
| StrOutputParser()
)
res = chain.invoke("how can langsmith help with testing?")
print(res)joke_chain = ChatPromptTemplate.from_template("告诉我一个关于 {topic}的笑话") | model
topic_chain = (
ChatPromptTemplate.from_template("告诉我一个关于{topic}的话题") | model
)
map_chain = RunnableParallel(joke=joke_chain, topic=topic_chain)
#并发执行chain
res = map_chain.invoke({"topic": "冰淇淋"})RunnablePassthrough
# RunnablePassthrough
runnable = RunnableParallel(
passed=RunnablePassthrough(),
extra=RunnablePassthrough.assign(mult=lambda x: x["num"] * 3),
modified=lambda x: x["num"] + 1,
)
runnable.invoke({"num": 1})
------
# 结果
{'extra': {'mult': 3, 'num': 1}, 'modified': 2, 'passed': {'num': 1}}当单独调用 RunnablePassthrough() 时,它只会简单地接收输入并直接传递出去。 当调用 RunnablePassthrough 的 assign 方法时,它会接收输入,并将assign 函数的额外参数添加到输入中。
RunnableLambda
def format_docs_into_text(docs):
doc_size = len(docs)
print('收到 {} 个文档'.format(doc_size))
return docs
chain = (
{
"context": itemgetter("question") | retriever | RunnableLambda(format_docs_into_text),
"question": itemgetter("question"),
}
| prompt
| model
| StrOutputParser()
)
res = chain.invoke({"question": "how can langsmith help with testing?"})
print(res)请注意,所有输入到这些函数的参数需要是单个参数。如果您有一个接受多个参数的函数,您应该编写一个包装器,该包装器接受单个输入并将其解包为多个参数。
@chain
功能上等同于将函数包装在上面所示的 RunnableLambda 构造函数中。
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import chain
prompt1 = ChatPromptTemplate.from_template("Tell me a joke about {topic}")
prompt2 = ChatPromptTemplate.from_template("What is the subject of this joke: {joke}")
@chain
def custom_chain(text):
prompt_val1 = prompt1.invoke({"topic": text})
output1 = ChatOpenAI().invoke(prompt_val1)
parsed_output1 = StrOutputParser().invoke(output1)
chain2 = prompt2 | ChatOpenAI() | StrOutputParser()
return chain2.invoke({"joke": parsed_output1})
custom_chain.invoke("bears")RunnableBranch
# 三个分支: langchain \ 百度 \ 缺省
langchain_chain = (
PromptTemplate.from_template(
"""你是langchain 专家,回答下面的问题:
问题: {question}
回答:"""
)
| model
)
baidu_chain = (
PromptTemplate.from_template(
"""你是百度AI专家,回答下面的问题:
问题: {question}
回答:"""
)
| model
)
general_chain = (
PromptTemplate.from_template(
"""
回答下面的问题:{question}
"""
)
| model
)
# “选择”分支
chain = (
PromptTemplate.from_template(
"""基于用户问题,选择这个问题是属于 `LangChain`, `百度`, or `其他`.
不要返回多余的词。
<question>
{question}
</question>
分类:"""
)
| model
| StrOutputParser()
)
def route(info):
if "百度" in info["topic"].lower():
return baidu_chain
elif "langchain" in info["topic"].lower():
return langchain_chain
else:
return general_chain
full_chain = {"topic": chain, "question": lambda x: x["question"]} | RunnableLambda(route)
res = full_chain.invoke({"question": "我如何使用百度?"})
print(res)runnable.bind()
调用runnable时,需要加入一些常量参数,它既不是前一个runnable的输出,也不是用户的输入,可以使用bind()
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Write out the following equation using algebraic symbols then solve it. Use the format\n\nEQUATION:...\nSOLUTION:...\n\n",
),
("human", "{equation_statement}"),
]
)
model = ChatOpenAI(temperature=0)
runnable = (
{"equation_statement": RunnablePassthrough()} | prompt | model | StrOutputParser()
)
print(runnable.invoke("x raised to the third plus seven equals 12"))
EQUATION: x^3 + 7 = 12
SOLUTION:
Subtract 7 from both sides:
x^3 = 5
Take the cube root of both sides:
x = ∛5
想要在SOLUTION就停止输出
runnable = (
{"equation_statement": RunnablePassthrough()}
| prompt
| model.bind(stop="SOLUTION")
| StrOutputParser()
)
print(runnable.invoke("x raised to the third plus seven equals 12"))bind_tools()
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
},
"required": ["location"],
},
},
}
]最外层:type,function
function层:name,description,parameters
parameters层:type,properties,required
。。。
model = ChatOpenAI(model="gpt-3.5-turbo-1106").bind(tools=tools)
model.invoke("What's the weather in SF, NYC and LA?")MultiQueryRetriever(多查询检索)
对于每个查询,它检索一组相关的文档,并取所有查询的独特并集,以获得一组可能相关的更大文档集合。通过为同一问题生成多个视角,多查询检索器可能能够克服基于距离的检索的一些局限性,并获取更丰富的结果集。
基于某个问题,从不同角度提出新问题,每个新问题从数据库中召回文本
os.environ['OPENAI_API_KEY'] = 'sk-gm0NJjYKwvRNRxstpWyEV1zDQvX9tfwNhlt8pjB7hlWvIDNt'
os.environ['OPENAI_BASE_URL'] = 'https://api.chatanywhere.tech/v1'
embeddings = OpenAIEmbeddings()
chat = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
connection = "postgresql+psycopg://postgres:12345678@localhost:5432/vector_store_1"
collection_name = "first_try"
vectorstore = PGVector(
embeddings=embeddings,
collection_name=collection_name,
connection=connection,
use_jsonb=True,
)
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=vectorstore.as_retriever(),
llm=chat,
)
question = '请介绍一下最近一届冰雪大世界。'
docs = retriever_from_llm.get_relevant_documents(query=question)
print(docs)MultiVectorRetriever
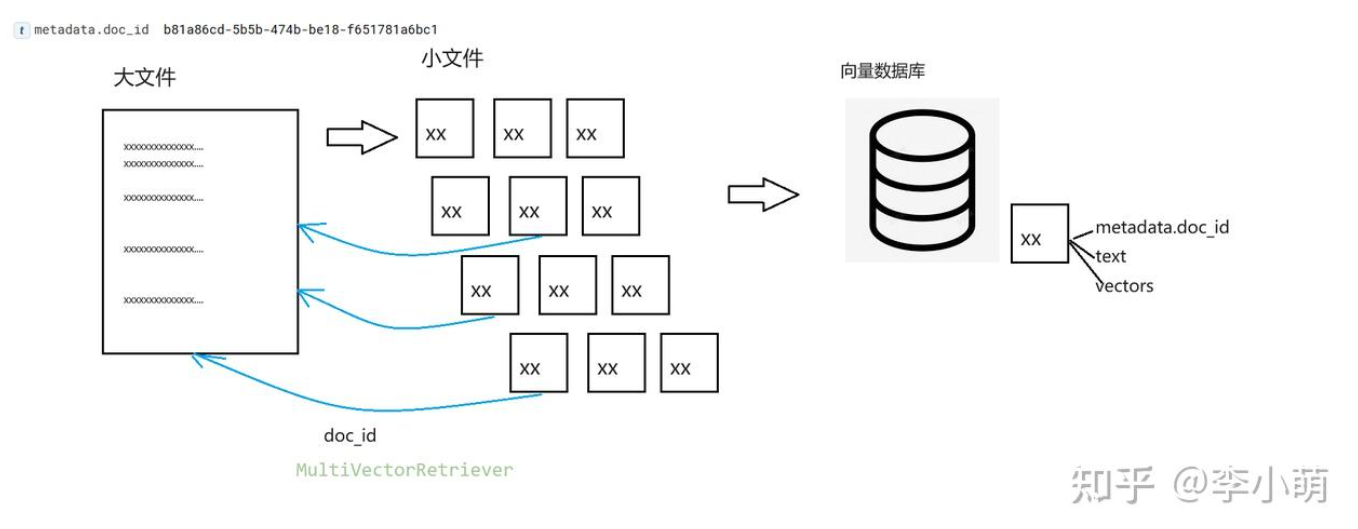
import os
from uuid import uuid4
from langchain import hub
from langchain.agents import create_openai_tools_agent, AgentExecutor
from langchain.retrievers import EnsembleRetriever, MultiQueryRetriever, MultiVectorRetriever
from langchain.storage import InMemoryByteStore
from langchain.tools.retriever import create_retriever_tool
from langchain_community.chat_models.azure_openai import AzureChatOpenAI
from langchain_community.document_loaders.web_base import WebBaseLoader
from langchain_community.embeddings import HuggingFaceEmbeddings, QianfanEmbeddingsEndpoint
from langchain_community.retrievers import ElasticSearchBM25Retriever
from langchain_community.vectorstores.chroma import Chroma
from langchain_community.vectorstores.elasticsearch import ElasticsearchStore
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
import uuid
# 设置一个随机ID
unique_id = uuid4().hex[0:8]
# 设置一个Log 名称
os.environ["LANGCHAIN_PROJECT"] = f" [MultiQueryRetriever] 小段 - {unique_id}"
# 设置 生成Langsmith 轨迹
# os.environ["LANGCHAIN_TRACING_V2"] = 'true'
# 填写你的 API KEY
os.environ["LANGCHAIN_API_KEY"] = os.getenv('MY_LANGCHAIN_API_KEY')
if __name__ == '__main__':
# 本地 BGE 模型
bge_en_v1p5_model_path = "D:\\LLM\\Bge_models\\bge-base-en-v1.5"
# 使用GPU
embeddings_model = HuggingFaceEmbeddings(
model_name=bge_en_v1p5_model_path,
model_kwargs={'device': 'cuda:0'},
encode_kwargs={'batch_size': 32, 'normalize_embeddings': True, }
)
# Elastic Search
# 向量数据库
vectorstore = ElasticsearchStore(
es_url=os.environ['ELASTIC_HOST_HTTP'],
index_name="index_sd_1024_vectors",
embedding=embeddings_model,
es_user="elastic",
vector_query_field='question_vectors',
es_password=os.environ['ELASTIC_ACCESS_PASSWORD']
)
# 解析并载入url
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=10000)
docs = text_splitter.split_documents(docs)
# 生成 大文件ID
doc_ids = [str(uuid.uuid4()) for _ in docs]
# 分割成小块
child_text_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
id_key = 'doc_id'
for i, doc in enumerate(docs):
_id = doc_ids[i]
_sub_docs = child_text_splitter.split_documents([doc])
for _doc in _sub_docs:
_doc.metadata[id_key] = _id
_doc.metadata['data_type'] = 'small_chunk'
# 将小的文本段向量化推送到ES
vectorstore.add_documents(_sub_docs)
# 将文件整个推送到ES(不做embedding)
tmp_doc = {
'text': doc.page_content,
'metadata': {
'data_type': 'big_chunk',
id_key: _id,
}
}
vectorstore.client.index(index='index_sd_1024_vectors', id=_id, document=tmp_doc)
# 获得小块
small_chunk_docs = vectorstore.similarity_search('justice breyer')
# 获得大块
# 获得不重复的大文本id
id_key = 'doc_id'
doc_uuid_list = []
for doc in small_chunk_docs:
if doc.metadata[id_key] not in doc_uuid_list:
doc_uuid_list.append(doc.metadata[id_key])
print('找到小文本[{}]'.format(doc.metadata[id_key]))
big_docs= []
for doc_uuid in doc_uuid_list:
res = vectorstore.client.get(index='index_sd_1024_vectors', id=doc_uuid)
big_docs.append(Document(page_content = res.body['_source']['text']))
pass
print('获得大块 [{}]个'.format(len(big_docs)))文档内容提取LLMChainExtractor
不是立即按原样返回检索到的文档,而是可以使用给定查询的上下文来压缩它们,以便只返回相关信息。这里的“压缩”既指压缩单个文档的内容,也指整体过滤掉文档。 要使用上下文压缩检索器,你需要:一个基础检索器和一个文档压缩器上下文压缩检索器将查询传递给基础检索器,获取初始文档并通过文档压缩器传递它们。文档压缩器接收一个文档列表,通过减少文档内容或完全删除文档来缩短列表。
compressor
# LLMChainExtractor
compressor = LLMChainExtractor.from_llm(qianfan_chat)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)提示词
"""Given the following question and context, extract any part of the context *AS IS* that is relevant to answer the question. If none of the context is relevant return NO_OUTPUT. \n\nRemember, *DO NOT* edit the extracted parts of the context.\n\n> Question: {question}\n> Context:\n>>>\n{context}\n>>>\nExtracted relevant parts:"""
#
"""在给定的问题和上下文中,提取与回答问题相关的任何部分AS IS。如果上下文中没有任何相关部分,请返回NO_OUTPUT。请记住,不要编辑提取的上下文部分。
问题:{question} 上下文:
{context}
提取的相关部分:"""from langchain_openai import ChatOpenAI,OpenAIEmbeddings
from langchain_postgres import PGVector
from langchain.retrievers import MultiQueryRetriever
from langchain.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.retrievers.document_compressors.chain_extract import LLMChainExtractor
from langchain.retrievers import ContextualCompressionRetriever
import os
if __name__ == '__main__':
os.environ['OPENAI_API_KEY'] = 'sk-gm0NJjYKwvRNRxstpWyEV1zDQvX9tfwNhlt8pjB7hlWvIDNt'
os.environ['OPENAI_BASE_URL'] = 'https://api.chatanywhere.tech/v1'
embeddings = OpenAIEmbeddings()
chat = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
connection = "postgresql+psycopg://postgres:12345678@localhost:5432/vector_store_1"
collection_name = "first_try"
vectorstore = PGVector(
embeddings=embeddings,
collection_name=collection_name,
connection=connection,
use_jsonb=True,
)
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
compressor = LLMChainExtractor.from_llm(chat)
question = "介绍一下第九届冰雪大世界。"
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=retriever
)
compressed_docs = compression_retriever.get_relevant_documents(query=question)
print(compressed_docs)文档内容过滤LLMChainFilter
提示词
template="Given the following question and context, return YES if the context is relevant to the question and NO if it isn't.\n\n> Question: {question}\n> Context:\n>>>\n{context}\n>>>\n> Relevant (YES / NO):")filter
# LLMChainFilter
doc_filter = LLMChainFilter.from_llm(qianfan_chat)
filter_retriever = ContextualCompressionRetriever(
base_compressor=doc_filter, base_retriever=retriever
)
filtered_docs = filter_retriever.get_relevant_documents(question)向量过滤EmbeddingsFilter
先将文件和你的问题转换成一种数学表达(嵌入),然后只挑出那些和你的问题在数学表达上相似的文件。这样就不需要每个文件都去麻烦那个大模型,省时省力
embedding_filter_embeddings_filter = EmbeddingsFilter(embeddings=embeddings_model, similarity_threshold=0.7)
# 直接过滤文档
filtered_docs = embedding_filter_embeddings_filter.compress_documents(docs[:10],question)
pass
embedding_filter_compression_retriever = ContextualCompressionRetriever(
base_compressor=embedding_filter_embeddings_filter, base_retriever=retriever
)
embedding_filter_docs = embedding_filter_compression_retriever.get_relevant_documents(question)
pass文档去重EmbeddingsRedundantFilter
docs = [
Document(page_content = "茉卷知识库"),
Document(page_content = "茉卷知识库"),
Document(page_content="同学你好!"),
Document(page_content="同学你好!"),
]
redundant_filter = EmbeddingsRedundantFilter(embeddings=embeddings_model)
filered_docs = redundant_filter.transform_documents(docs)文档管道DocumentCompressorPipeline
# 文本去重
redundant_filter = EmbeddingsRedundantFilter(embeddings=embeddings_model)
# 通过问题和文本的 语义相似度过滤
emb_filter = EmbeddingsFilter(embeddings=embeddings_model, similarity_threshold=0.6)
# 文档压缩
qianfan_compressor = LLMChainExtractor.from_llm(qianfan_chat)
# 建立管道: 过滤 + 压缩
pipeline_compressor = DocumentCompressorPipeline(
transformers=[emb_filter,redundant_filter,qianfan_compressor]
)
# 建立 语境压缩 Retriever
compression_retriever = ContextualCompressionRetriever(
base_compressor=pipeline_compressor, base_retriever=retriever
)
# 文档召回
compressed_docs = compression_retriever.get_relevant_documents(question)文档排序LongContextReorder
# 文档重排序
retriever = vectorstore.as_retriever(search_kwargs={"k": 10})
docs_pre = retriever.get_relevant_documents('Decomposition')
reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(docs_pre)rerank
import os
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import DocumentCompressorPipeline, EmbeddingsFilter, LLMChainExtractor
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.chat_models import ChatOpenAI
from langchain_community.document_transformers import EmbeddingsRedundantFilter
from langchain_community.embeddings import HuggingFaceEmbeddings
from BCEmbedding.tools.langchain import BCERerank
from langchain_postgres import PGVector
os.environ['OPENAI_API_KEY'] = 'sk-gm0NJjYKwvRNRxstpWyEV1zDQvX9tfwNhlt8pjB7hlWvIDNt'
os.environ['OPENAI_BASE_URL'] = 'https://api.chatanywhere.tech/v1'
chat = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
if __name__ == '__main__':
# 使用本地网易有道模型 BCE, 使用CPU
embedding_model_name = r'D:\LLM\bce-embedding-base_v1'
embedding_model_kwargs = {'device': 'cpu'}
embedding_encode_kwargs = {'batch_size': 32, 'normalize_embeddings': True, }
embed_model = HuggingFaceEmbeddings(
model_name=embedding_model_name,
model_kwargs=embedding_model_kwargs,
encode_kwargs=embedding_encode_kwargs
)
connection = "postgresql+psycopg://postgres:12345678@localhost:5432/vector_store_2"
collection_name = "second_try"
vectorstore = PGVector(
embeddings=embed_model,
collection_name=collection_name,
connection=connection,
use_jsonb=True,
)
retriever = vectorstore.as_retriever(search_kwargs={"k": 20})
query = '我最喜欢的电影是哪部?'
# 使用CPU
reranker_args = {'model': r'D:\LLM\bce-reranker-base_v1', 'top_n': 10, 'device': 'cpu'}
reranker = BCERerank(**reranker_args)
compression_retriever = ContextualCompressionRetriever(
base_compressor=reranker, base_retriever=retriever
)
# rerank 过滤文档
# docs = compression_retriever.get_relevant_documents(query)
# 文档分割器
text_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
# 向量过滤
embedding_filter = EmbeddingsFilter(embeddings=embed_model, similarity_threshold=0.6)
# 文档去重
redundant_filter = EmbeddingsRedundantFilter(embeddings=embed_model)
# 内容抽取
llm_extractor = LLMChainExtractor.from_llm(chat)
pipeline_compressor = DocumentCompressorPipeline(
transformers=[text_splitter, embedding_filter, redundant_filter, reranker, llm_extractor]
)
pipeline_retriever = ContextualCompressionRetriever(
base_compressor=pipeline_compressor, base_retriever=retriever
)
docs = pipeline_retriever.get_relevant_documents(query)
print(docs)
docs = pipeline_retriever.get_relevant_documents(query)经过分割、向量过滤、文档去重、rerank,最后只会少量较准确数据被抽取出来
区分用户角色
doc_list = []
owner_one_doc = docs[0]
owner_one_docs = text_splitter.create_documents([owner_one_doc.page_content])
# 加入metadata 信息,作者信息 userid_001
for i, doc in enumerate(owner_one_docs):
doc.metadata["author"] = ["userid_001"]
doc_list.append(doc)
owner_two_doc = docs[1]
owner_two_docs = text_splitter.create_documents([owner_two_doc.page_content])
# 加入metadata 信息,作者信息 userid_022
for i, doc in enumerate(owner_two_docs):
doc.metadata["author"] = ["userid_022"]
doc_list.append(doc) # 你需要搜索谁的数据?
user_id= "userid_001"
# user_id = "userid_002"
# 基于user_id, 定义你的过滤器
filter_criteria = [{"term": {"metadata.author.keyword": user_id}}]
# 生成只过滤user_id的检索器
special_retriever = vectorstore.as_retriever(search_kwargs={'filter': filter_criteria}) # 测试检索器效果,应该只能搜到metadata.author.keyword 为 user_id 的文档
test_chain = RunnableParallel(
{"context": special_retriever, "question": RunnablePassthrough()}
)
test_docs = test_chain.invoke("谁在2007年荣登“世界首富”的宝座,成了财富和成功的象征?")信息提取
schema
from typing import Optional
from typing import List, Optional
from langchain_core.pydantic_v1 import BaseModel, Field
class Person(BaseModel):
"""Information about a person."""
# ^ Doc-string for the entity Person.
# This doc-string is sent to the LLM as the description of the schema Person,
# and it can help to improve extraction results.
# Note that:
# 1. Each field is an `optional` -- this allows the model to decline to extract it!
# 2. Each field has a `description` -- this description is used by the LLM.
# Having a good description can help improve extraction results.
name: Optional[str] = Field(..., description="The name of the person")
hair_color: Optional[str] = Field(
..., description="The color of the peron's hair if known"
)
height_in_meters: Optional[str] = Field(
..., description="Height measured in meters"
)
class Data(BaseModel):
"""Extracted data about people."""
# Creates a model so that we can extract multiple entities.
people: List[Person]name,hair_color,height_in_meters: 需要大模型抽取的信息
Optional: 告诉模型可以不输出,别编
description: 告诉模型变量的意思是什么
提供一些例子给到大模型。
这些例子不通过提示词,而是通过伪造大模型的function call输出历史,反馈给大模型
import os
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from typing import List, Optional
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI, AzureChatOpenAI
import uuid
from typing import Dict, List, TypedDict
from langchain_core.messages import (
AIMessage,
BaseMessage,
HumanMessage,
SystemMessage,
ToolMessage,
)
from langchain_core.pydantic_v1 import BaseModel, Field
if __name__ == '__main__':
#
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"您是一个专业的提取信息专家。 "
"只从文本中提取相关信息。"
"如果你不知道请求提取的属性值,请将该属性值返回为null。",
),
# ↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
MessagesPlaceholder("examples"), # <-- EXAMPLES! 最后invoke的时候,会被替换成examples
# ↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑
("human", "{text}"),
]
)
class Book(BaseModel):
book_name: Optional[str] = Field(..., description="书的名称")
writer: Optional[str] = Field( ..., description="书的作者")
content:Optional[str] = Field( ..., description="书大概内容介绍")
date :Optional[str] = Field( ..., description="预计出版时间")
class Data(BaseModel):
books: List[Book]
class Example(TypedDict):
"""A representation of an example consisting of text input and expected tool calls.
For extraction, the tool calls are represented as instances of pydantic model.
"""
input: str # This is the example text
tool_calls: List[BaseModel] # Instances of pydantic model that should be extracted
def tool_example_to_messages(example: Example) -> List[BaseMessage]: #接受一个Example类型的参数,返回一个BaseMessage类型的列表
messages: List[BaseMessage] = [HumanMessage(content=example["input"])]
openai_tool_calls = []
for tool_call in example["tool_calls"]:
openai_tool_calls.append(
{
"id": str(uuid.uuid4()),
"type": "function",
"function": {
"name": tool_call.__class__.__name__,
"arguments": tool_call.json(),
},
}
)
messages.append(
AIMessage(content="", additional_kwargs={"tool_calls": openai_tool_calls})
)
tool_outputs = example.get("tool_outputs") or [
"You have correctly called this tool."
] * len(openai_tool_calls)
for output, tool_call in zip(tool_outputs, openai_tool_calls):
messages.append(ToolMessage(content=output, tool_call_id=tool_call["id"]))
return messages
examples = [
(
"""
《美棠来信:我们一家人》
作者:饶平如
出品方/出版社:小阅读Random
预计出版时间:2023年6月
(书封待定,图为作者饶平如)
继《平如美棠》后,《美棠来信》更加细致地呈现出家书中一个中国普通家庭的记忆。1973年至1979年,饶平如下放安徽,毛美棠留在上海照顾家庭。不久,家中年长的孩子们也响应知识青年上山下乡,去安徽、江西等地下乡。分散在各地的家庭成员,唯一连接他们亲情的,是一封封往来两地的家书。
本书收录了饶平如在1973年到1979年之间收到的来自妻子美棠和孩子的近两百封家书。在那个通讯不便的年代,在这些家书里,他们互相汇报生活近况,通报生活上遇到的困难,给对方出谋划策,嘘寒问暖,这些家书支撑他们度过了两地分散的艰难时期,同时也是那个年代一个普通中国家庭生活的真实侧写。
""",
Book(book_name='美棠来信:我们一家人', writer='饶平如', content="""继《平如美棠》后,《美棠来信》更加细致地呈现出家书中一个中国普通家庭的记忆。1973年至1979年,饶平如下放安徽,毛美棠留在上海照顾家庭。不久,家中年长的孩子们也响应知识青年上山下乡,去安徽、江西等地下乡。分散在各地的家庭成员,唯一连接他们亲情的,是一封封往来两地的家书。
本书收录了饶平如在1973年到1979年之间收到的来自妻子美棠和孩子的近两百封家书。在那个通讯不便的年代,在这些家书里,他们互相汇报生活近况,通报生活上遇到的困难,给对方出谋划策,嘘寒问暖,这些家书支撑他们度过了两地分散的艰难时期,同时也是那个年代一个普通中国家庭生活的真实侧写""",date='2023年6月'),
), #还可以多加例子元组
]
messages = []
for text, tool_call in examples:
messages.extend(
tool_example_to_messages({"input": text, "tool_calls": [tool_call]})
)
# Azure Openai
llm = AzureChatOpenAI(
openai_api_version="2024-02-15-preview",
azure_deployment=os.getenv('DEPLOYMENT_NAME_GPT3_4K_JP'),
temperature=0,
)
runnable = prompt | llm.with_structured_output(
schema=Data,
method="function_calling",
include_raw=False,
)
for _ in range(5):
text = """
《浮生余情》(暂名)
作者:格非
出品方/出版社:译林出版社
预计出版时间:2023年8月
(书封待定,图为作者格非)
《浮生余情》是格非时隔四年推出的最新重磅长篇小说,叙写了1980年代至今四十余年的漫长时间里,四个彼此关联的人物的命运流转。
四个故事的主人公分别从江浙、北京、甘肃和天津四个地方来到北京的春台路21号——位于后厂村的中关村软件园。他们均供职于同一家现代物联网企业,彼此在生活中多有交集。四个故事由亲情、爱情的本能情感走向对自我与他者关系建构的哲学思考,进而关注现代人当下的存在方式与情感命题。
《大地上的家乡》
作者:刘亮程
出品方/出版社:译林出版社
预计出版时间:2023年6月
(书封待定,图为作者刘亮程)
1998年,刘亮程站在乌鲁木齐的夕阳中,回望自己的家乡黄沙梁,写就《一个人的村庄》。此后,他在城市结婚、生子、写作、生活。2013年,刘亮程入住新疆木垒书院菜籽沟村落,重返晴耕雨读的田园生活,仿佛又回到早年的鸡鸣狗吠、虫鸣鸟语、风声落叶中,进入写作《一个人的村庄》时的状态。
菜籽沟村堆满故事,早晨做梦的气味被一只狗闻见,在一棵大树下慢慢变老,散步于开满窗户的山坡,看从天坑外背土豆的人……这些飘在空中被人视若寻常的故事,均收在了新书《大地上的家乡》里。
《俗世奇人新增本》
作者: 冯骥才
出品方/出版社: 人民文学出版社
预计出版时间:2023年1月
“俗世奇人”系列是当代文化大家冯骥才先生的代表作,也是当代文学的重要收获之一。天津卫本是水陆码头,居民五方杂处,性格迥然相异,冯骥才随想随记,每人一篇,冠之总名《俗世奇人》耳。
2022年末,冯先生又创作了18篇“俗世奇人”系列新作,包括《欢喜》《小尊王五》《田大头》《谢二虎》等精彩作品,还专程为书中人物绘制了20余幅精美人物插画。18篇新作延续了之前一贯的写作手法、传奇风格和创作水准,艺术性层面更为灵动丰富,令人不忍释卷。
《四》(书名待定)
作者:杨本芬
出品方/出版社:乐府文化
预计出版时间:2023年7月
(书封待定,图为作者杨本芬)
杨本芬奶奶的第四本书,收入四个中短篇,写四个不同的人。对妈妈的回忆,对哥哥的眷恋,以及,哪怕是一位农妇,一个捡垃圾的老太太,依然拥有的,身为女性的,骄傲。也许,这本书可以叫《我的思念,她的骄傲》。
《木星时刻》
作者:李静睿
出品方/出版社:小阅读Random
预计出版时间:2023年5月
(书封待定,上图为作者李静睿)
李静睿的最新短篇小说集,收录具有科幻风格的《木星时刻》、充满粗粝现实感的《温榆河》等8部短篇小说。
李静睿在《木星时刻》里构建了一个依法由AI治理的未来社会,人们在其中享有健康的饮食和生活方式、绝对安全的生存环境,以及完美的AI管家,唯独没有自由。于是,作为“最后一代上学还能逃课的人类”的主人公夫妻二人,决心踏上一场“肖申克”式的逃亡之旅……
"""
print(runnable.invoke({"text": text, "examples": messages}))
passtool_calls
{'id': '932e3864-db6b-4888-a1ba-566609d6530d', 'type': 'function', 'function': {'name': 'Book', 'arguments': '{"book_name": "美棠来信:我们一家人", "writer": "饶平如", "content": "继《平如美棠》后,《美棠来信》更加细致..", "date": "2023年6月"}'}}
将模型温度设置为0。
改进提示。提示应精确且切中要害。
schema 中正确描述参数内容。
提供参考示例!多样化的示例有助于提高性能,包括不应提取任何内容的示例。
如果您有很多示例,请使用检索器获取最相关的示例。
使用最佳可用的LLM/聊天模型(例如,gpt-4、claude-3等)进行基准测试。
如果模式非常大,尝试将其拆分为多个较小的模式,分别运行提取并合并结果。
确保模式允许模型拒绝提取信息。
添加验证/更正步骤(要求LLM纠正或验证提取结果)。
子链路由
from langchain_anthropic import ChatAnthropic
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
chain = (
PromptTemplate.from_template(
"""Given the user question below, classify it as either being about `LangChain`, `Anthropic`, or `Other`.
Do not respond with more than one word.
<question>
{question}
</question>
Classification:"""
)
| ChatAnthropic(model_name="claude-3-haiku-20240307")
| StrOutputParser()
)
# chain.invoke({"question": "how do I call Anthropic?"})
langchain_chain = PromptTemplate.from_template(
"""You are an expert in langchain. \
Always answer questions starting with "As Harrison Chase told me". \
Respond to the following question:
Question: {question}
Answer:"""
) | ChatAnthropic(model_name="claude-3-haiku-20240307")
anthropic_chain = PromptTemplate.from_template(
"""You are an expert in anthropic. \
Always answer questions starting with "As Dario Amodei told me". \
Respond to the following question:
Question: {question}
Answer:"""
) | ChatAnthropic(model_name="claude-3-haiku-20240307")
general_chain = PromptTemplate.from_template(
"""Respond to the following question:
Question: {question}
Answer:"""
) | ChatAnthropic(model_name="claude-3-haiku-20240307")
def route(info):
if "anthropic" in info["topic"].lower():
return anthropic_chain
elif "langchain" in info["topic"].lower():
return langchain_chain
else:
return general_chain
from langchain_core.runnables import RunnableLambda
full_chain = {"topic": chain, "question": lambda x: x["question"]} | RunnableLambda(
route
)
full_chain.invoke({"question": "how do I use Anthropic?"})配置运行时链内部结构
Configurable Fields
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import ConfigurableField
from langchain_openai import ChatOpenAI
model = ChatOpenAI(temperature=0).configurable_fields(
temperature=ConfigurableField(
id="llm_temperature",
name="LLM Temperature",
description="The temperature of the LLM",
)
)
model.invoke("pick a random number")上述,我们将temperature定义为一个ConfigurableField,可以在运行时进行设置。为此,我们使用with_config方法,如下所示:
model.with_config(configurable={"llm_temperature": 0.9}).invoke("pick a random number")
与HubRunnables一起使用
from langchain.runnables.hub import HubRunnable
prompt = HubRunnable("rlm/rag-prompt").configurable_fields(
owner_repo_commit=ConfigurableField(
id="hub_commit",
name="Hub Commit",
description="The Hub commit to pull from",
)
)
prompt.invoke({"question": "foo", "context": "bar"})
prompt.with_config(configurable={"hub_commit": "rlm/rag-prompt-llama"}).invoke(
{"question": "foo", "context": "bar"}
)通过相似性选择示例
from langchain_chroma import Chroma
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate
from langchain_openai import OpenAIEmbeddings
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="Input: {input}\nOutput: {output}",
)
# Examples of a pretend task of creating antonyms.
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
example_selector = SemanticSimilarityExampleSelector.from_examples(
# The list of examples available to select from.
examples,
# The embedding class used to produce embeddings which are used to measure semantic similarity.
OpenAIEmbeddings(),
# The VectorStore class that is used to store the embeddings and do a similarity search over.
Chroma,
# The number of examples to produce.
k=1,
)
similar_prompt = FewShotPromptTemplate(
# We provide an ExampleSelector instead of examples.
example_selector=example_selector,
example_prompt=example_prompt,
prefix="Give the antonym of every input",
suffix="Input: {adjective}\nOutput:",
input_variables=["adjective"],
)
# Input is a feeling, so should select the happy/sad example
print(similar_prompt.format(adjective="worried"))合并连续的相同类型消息(merge_message_runs)
from langchain_core.messages import (
AIMessage,
HumanMessage,
SystemMessage,
merge_message_runs,
)
messages = [
SystemMessage("you're a good assistant."),
SystemMessage("you always respond with a joke."),
HumanMessage([{"type": "text", "text": "i wonder why it's called langchain"}]),
HumanMessage("and who is harrison chasing anyways"),
AIMessage(
'Well, I guess they thought "WordRope" and "SentenceString" just didn\'t have the same ring to it!'
),
AIMessage("Why, he's probably chasing after the last cup of coffee in the office!"),
]
from langchain_anthropic import ChatAnthropic
llm = ChatAnthropic(model="claude-3-sonnet-20240229", temperature=0)
# Notice we don't pass in messages. This creates
# a RunnableLambda that takes messages as input
merger = merge_message_runs()
chain = merger | llm
chain.invoke(messages)messages过滤
from langchain_core.messages import (
AIMessage,
HumanMessage,
SystemMessage,
filter_messages,
)
messages = [
SystemMessage("you are a good assistant", id="1"),
HumanMessage("example input", id="2", name="example_user"),
AIMessage("example output", id="3", name="example_assistant"),
HumanMessage("real input", id="4", name="bob"),
AIMessage("real output", id="5", name="alice"),
]
filter_messages(messages, include_types="human")
filter_messages(messages, exclude_names=["example_user", "example_assistant"])
filter_messages(messages, include_types=[HumanMessage, AIMessage], exclude_ids=["3"])
# pip install -U langchain-anthropic
from langchain_anthropic import ChatAnthropic
llm = ChatAnthropic(model="claude-3-sonnet-20240229", temperature=0)
# Notice we don't pass in messages. This creates
# a RunnableLambda that takes messages as input
filter_ = filter_messages(exclude_names=["example_user", "example_assistant"])
chain = filter_ | llm
chain.invoke(messages)