
langchian RAG
初步RAG
文档载入
path = './test'
from langchain_community.document_loaders import DirectoryLoader,TextLoader
text_loader_kwargs = {"autodetect_encoding": True}#自动检测编码类型
loader = DirectoryLoader(path, glob="**/*.txt", loader_cls=TextLoader,loader_kwargs=text_loader_kwargs)
docs = loader.load()split
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_spliter = RecursiveCharacterTextSplitter(
chunk_size = 100,
chunk_overlap = 20,
length_function = len,
)
doc_list = []
for doc in docs:
tmp_docs = text_spliter.create_documents([doc.page_content])
doc_list += tmp_docs向量存储
from langchain_openai import OpenAIEmbeddings
from langchain_core.documents import Document
from langchain_postgres import PGVector
from langchain_postgres.vectorstores import PGVector
import os
os.environ['OPENAI_API_KEY'] = 'sk-gm0NJjYKwvRNRxstpWyEV1zDQvX9tfwNhlt8pjB7hlWvIDNt'
os.environ['OPENAI_BASE_URL'] = 'https://api.chatanywhere.tech/v1'
embeddings = OpenAIEmbeddings()
connection = "postgresql+psycopg://postgres:12345678@localhost:5432/vector_store"
collection_name = "first_try"
vectorstore = PGVector(
embeddings=embeddings,
collection_name=collection_name,
connection=connection,
use_jsonb=True,
)
# vectorstore.add_documents(doc_list)#只需要放一次检索生成
from langchain_openai import ChatOpenAI
from langchain import hub
from langchain_core.runnables.passthrough import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
retriever = vectorstore.as_retriever()
prompt = hub.pull('rlm/rag-prompt')
chat = ChatOpenAI(temperature=0.9, model_name="gpt-3.5-turbo-0125")
def format_docs(docs):
return '\n\n'.join(doc.page_content for doc in docs)#把内容连接到一块
rag_chain = (
{'context':retriever | format_docs, 'question': RunnablePassthrough()}
| prompt
| chat
| StrOutputParser()
)
while True:
query_text = input("请输入你的问题:")
if 'exit' in query_text:
break
print('AI需要回答的问题[{}]\n'.format(query_text))
res = rag_chain.invoke(query_text)
print(res)细致一点
文档检索
retriever = vectorstore.as_retriever(search_type = 'similarity', search_kwargs = {'k': 6})
retriever_docs = retriever.invoke('what are the approches to task decomposition?')
#输出的是一个个文档,Document对象,需要进一步处理提示词定制
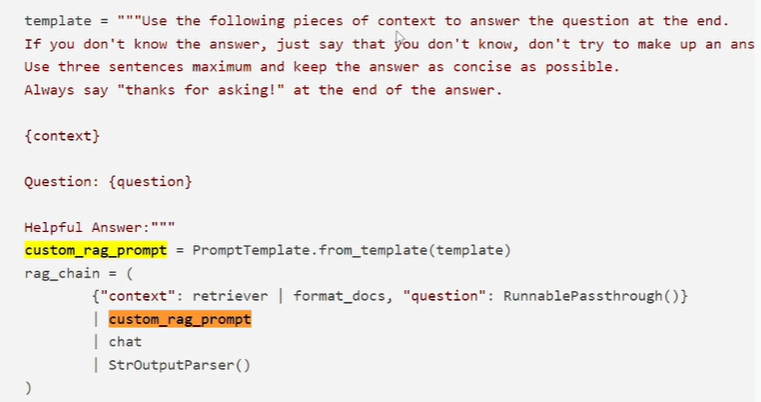
context就是检索出来的自己库里的内容
RunnablePassthrough就是最后invoke里的字符串
返回结果包含文档
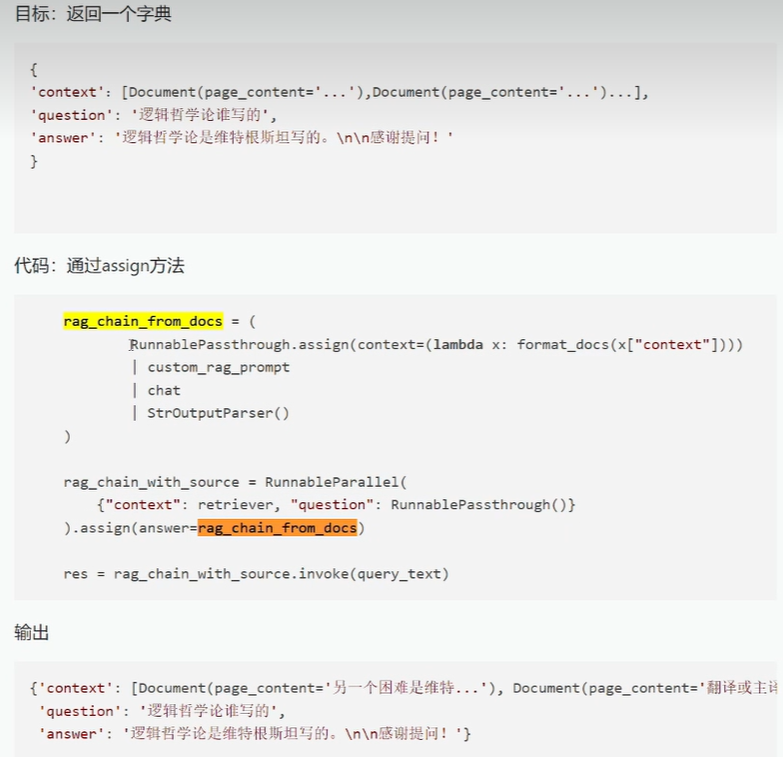
runnableparallel返回一个由文档组成的字典,将其传入一个链
链的第一步用format_docs(拼接成字符串)处理字典的context内容,变成字符串
添加对话历史

messageplaceholder就是对聊天历史的一个抽象,这个prompt里就是系统提示词加上历史加上用户问题
下面invoke时模拟了一个历史

contextualized_question函数判断传入的字典是否有chat_history,有就返回上一块的链,否则就返回字典里的question
import os
from langchain_openai import ChatOpenAI,OpenAIEmbeddings
from langchain_postgres import PGVector
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate,MessagesPlaceholder
from langchain_core.runnables import RunnablePassthrough
if __name__ == '__main__':
os.environ['OPENAI_API_KEY'] = 'sk-gm0NJjYKwvRNRxstpWyEV1zDQvX9tfwNhlt8pjB7hlWvIDNt'
os.environ['OPENAI_BASE_URL'] = 'https://api.chatanywhere.tech/v1'
embeddings = OpenAIEmbeddings()
chat = ChatOpenAI(model_name="gpt-3.5-turbo-0125", temperature=0.9)
connection = "postgresql+psycopg://postgres:12345678@localhost:5432/vector_store_1"
collection_name = "first_try"
vectorstore = PGVector(
embeddings=embeddings,
collection_name=collection_name,
connection=connection,
use_jsonb=True,
)
retriever = vectorstore.as_retriever(search_type = 'similarity', search_kwargs={"k": 6})
def format_docs(docs):
return '\n\n'.join(doc.page_content for doc in docs)
#检索回答链
qa_question_prompt = '''你是一个问答机器人,用提供的context回答问题。如果你不知道答案,直接说明你不知道。
{context}'''
qa_prompt = ChatPromptTemplate.from_messages([
('system', qa_question_prompt),
MessagesPlaceholder(variable_name='chat_history'),
('human', '{question}')
])
def contextualized_question(input:dict):
if input.get('chat_history'):
return contextualized_q_chain #有历史就回一个补全了的链
else:
return input['question'] #没历史就返回这个问题
#基于上下文补全链,怎么感觉有点多此一举
contextualized_q_system_prompt = '''给定一个聊天记录和在聊天记录中引用上下文的最新用户问题,
制定一个不需要聊天记录也能理解的独立问题。不要回答问题,只要在需要的时候重新表述,否则就原样返回'''
contextualized_q_prompt = ChatPromptTemplate.from_messages([
('system', contextualized_q_system_prompt),
MessagesPlaceholder(variable_name='chat_history'),
('human', '{question}')
])
contextualized_q_chain = contextualized_q_prompt | chat | StrOutputParser()
chat_history = []
#最终链
rag_chain = (
RunnablePassthrough.assign(
context = contextualized_question | retriever | format_docs
)
| qa_prompt
| chat
)
while True:
query_text = input('你的问题是:')
if 'exit' in query_text:
break
print('AI需要回答的问题是:[{}]\n'.format(query_text))
ai_msg = rag_chain.invoke({'question': query_text, 'chat_history': chat_history})
chat_history.extend([HumanMessage(content=query_text), ai_msg])
print(ai_msg.content)
流式输出
for chunk in rag_chain.stream(query_text):
print(chunk,end='',flush=True)视频中出现了打印出一个个字典的情况,处理如下
output = {}
curr_key = None
for chunk in rag_chain.stream(query_text):
# print(chunk,end='',flush=True)
for key in chunk:
if key not in output:
output[key] = chunk[key]
else:
output[key] += chunk[key]
if key != curr_key:
print(f'\n\n{key}:{chunk[key]}',end='',flush=True)
else:
print(chunk[key],end='',flush=True)
curr_key = key
output不同用户的数据检索
pgvector支持过滤,一些操作符可以看文档最后:PGVector | 🦜️🔗 LangChain
添加数据时,需要增加metadata信息
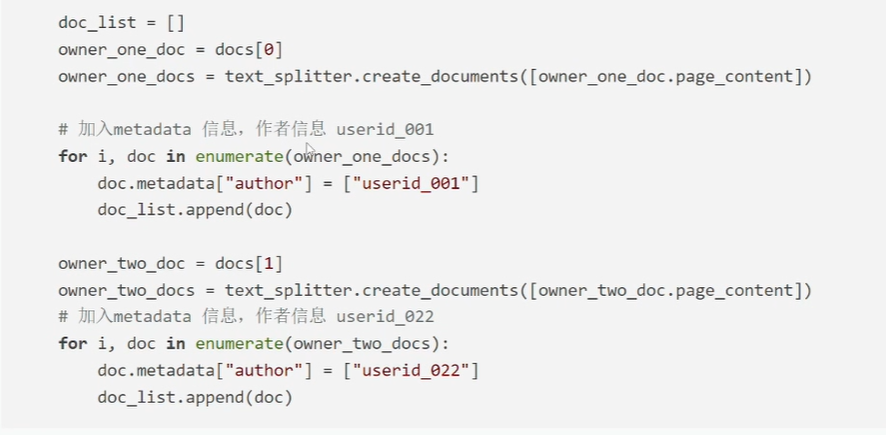
具体看这个视频:[茉卷知识库]#Langchain教程 [28] RAG实战 Day4_哔哩哔哩_bilibili
CRAG(纠正式RAG)
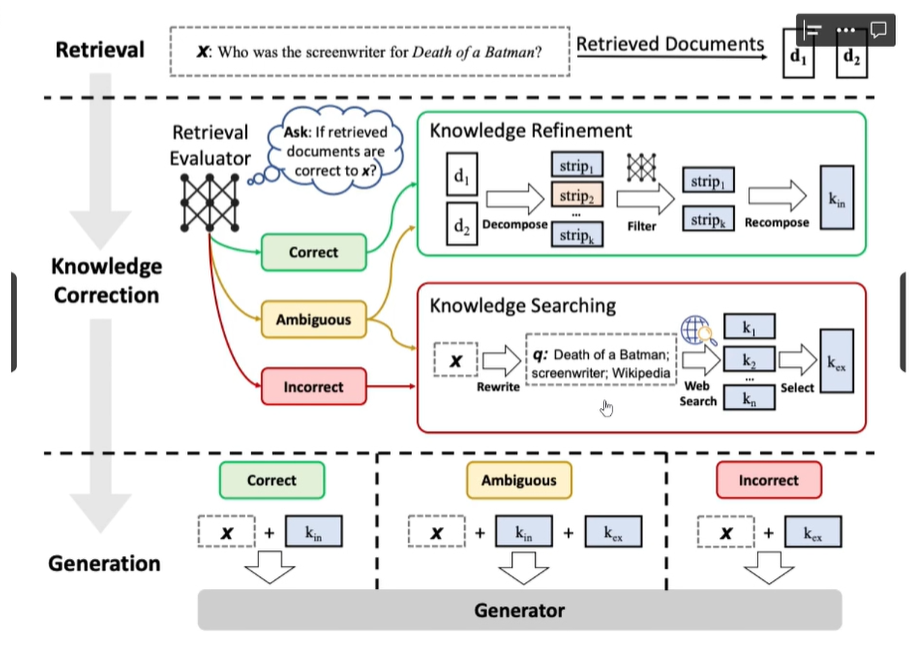
correct:
如果至少有一个文档相关性超过阈值,继续生成过程
生成之前执行知识精炼
文档分割成条(strip),进行评分,过滤不相关条
other:
所有文档相关性都低于阈值,或者评分器不稳定,会去寻求额外数据源
使用网络搜索来补充
langchian则跳过了知识精炼部分

评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果